
Gemini 3.1 and Google's Multimodal AI Strategy Explained: How Google Is Building the Future of AI
- Shaikhmuizz javed
- May 26
- 31 min read

By Muizz Shaikh | FourfoldAI Published: May 2026
Introduction
Traditional AI was built for text. Underneath every early chatbot, search box, and autocomplete suggestion was a system that fundamentally thought in words — converting everything else into language first, then processing it, then converting it back. That worked well enough when AI was a novelty. It fails completely when the real world sends you a customer support audio recording, a live video feed, a 3-million-line codebase, or a financial document stack.
The world does not communicate in clean text prompts. It communicates in video meetings, voice memos, product images, scanned PDFs, and sprawling code repositories. Gemini 3.1 and Google's Multimodal AI Strategy address this gap directly — not by adding modalities on top of an existing language model, but by building a neural architecture that handles text, audio, image, video, and code natively from the ground up.
Google's announcement at I/O 2026 made one thing explicitly clear: the company is no longer building AI assistants. It is building AI infrastructure. Sundar Pichai's framing of "the agentic Gemini era" was not marketing language — it was an architectural declaration. Gemini is moving from a product that responds to queries into a distributed system that takes action on your behalf, continuously, across every surface Google owns.

At FourfoldAI, we have tracked hundreds of AI tool evaluations and enterprise deployment cycles. The honest observation is this: true AI ROI is rarely found in local productivity hacks like autocompleting a line of code or summarising a document. It accumulates in platform-layer workflows — systems that run autonomously, connect to live business data, execute multi-step operations, and operate within enterprise security guardrails around the clock. That is precisely what Gemini 3.1 and Google's broader agentic infrastructure are now capable of delivering. The question for businesses is no longer whether to engage, but how to engage strategically.
What Is Gemini 3.1?
Gemini 3.1 in Simple Terms
Think of most AI models as translators. When you upload an audio file to a typical system, it first converts the audio to text, reasons over the text, then produces a response. Every conversion step introduces latency, loses nuance, and strips out contextual signals — the pause before a customer says "I'm frustrated," the tone shift that signals hesitation, the visual element in a frame that changes the meaning of the spoken words entirely.
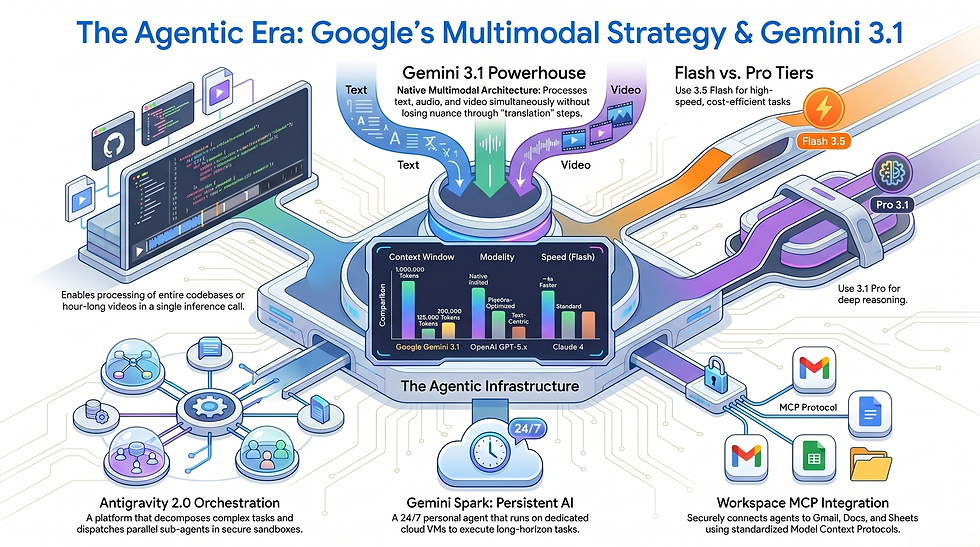
Gemini 3.1 is an engine designed to process multiple streams of sensory data simultaneously. Rather than converting audio to text, or video to text, and then reasoning over those text translations, Gemini 3.1 Pro holds all modalities in its neural architecture at once. The model was trained natively on text, images, audio, video, and code from day one — not assembled from separate specialised modules after training was complete.
Released by Google DeepMind on February 19, 2026, Gemini 3.1 Pro is the refined iteration of the Gemini 3 Pro model that launched in November 2025. It represents an architectural maturation rather than a generational leap: tighter reasoning, improved long-context coherence, and meaningfully stronger performance on agentic coding tasks. The model carries a 1-million-token context window, a specification that fundamentally changes what enterprises can actually do with a single inference call.
Core Capabilities
Text Understanding and Reasoning
Gemini 3.1 Pro's reasoning capability is its clearest differentiator at the frontier level. The model demonstrates high performance across complex logical reasoning benchmarks, with Gemini 3's lineage already establishing strong scores on GPQA Diamond and SimpleBench. The "deep thinking" mode engages extended chain-of-thought processing before producing a response, which significantly improves performance on multi-step problems — mathematics, legal interpretation, financial modelling, and systems debugging.
What makes this practically meaningful is the combination of reasoning depth with context breadth. A model that reasons well but can only hold 128,000 tokens requires engineers to chunk documents, build retrieval pipelines, and manage context manually. Gemini 3.1 Pro with a million-token window ingests an entire legal contract library, reasons across all of it, and surfaces a synthesis — in a single call.
Image and Video Reasoning
The 1-million-token context window transforms video analysis from a theoretical capability into a practical workflow tool. Hour-long video recordings — a product teardown session, a recorded customer interview series, a security camera archive — can be submitted in a single prompt. The model does not sample keyframes or summarise segments. It processes the full temporal sequence, tracking continuity, change, and context across the entire duration.
For enterprises, this is immediately applicable in quality assurance, compliance review, training video analysis, and competitive intelligence. Marketing teams can submit hours of competitor video content and receive structured analyses of messaging patterns, tone shifts, and visual strategies.
Audio Processing
One capability that consistently gets underestimated is Gemini's direct audio processing. The model does not transcribe audio to text before analysis. It reads the raw audio signal — which means it captures inflection, emotional tone, speech rhythm, and acoustic context that a transcript simply cannot contain. A call centre recording processed through Gemini 3.1 Pro yields more than what was said. It captures how it was said, and when the conversation dynamics shifted. That distinction matters enormously for customer experience, compliance, and training applications.
Code Generation and Engineering
Gemini 3.1 Pro's code reasoning capabilities have improved substantially compared to earlier Gemini generations. The model performs well on SWE-bench Verified — an industry benchmark designed to evaluate how models handle real-world software engineering tasks drawn from open-source GitHub repositories. The combination of strong code reasoning and a massive context window makes it genuinely useful for the tasks that historically required senior developers: navigating unfamiliar large codebases, identifying cross-file dependencies, tracing bugs through layered abstractions, and proposing architectural changes that account for system-wide implications.
Gemini 3.5 Flash: The Speed-Efficiency Frontier Model
Announced at Google I/O 2026 and immediately available via the Gemini API, Gemini 3.5 Flash is the headline model for the agentic era. Google's own framing positions it as frontier-level intelligence at Flash model speeds and pricing — running roughly four times faster on output tokens per second compared to other frontier models, and costing less than half the price of comparable alternatives. Sundar Pichai walked through the cost arithmetic publicly: companies processing approximately a trillion tokens per day could save over a billion dollars annually by shifting 80% of their workload to Gemini 3.5 Flash.
The model surpasses Gemini 3.1 Pro on coding, agentic task execution, and multimodal benchmarks. For high-volume enterprise deployments — document processing pipelines, automated customer workflows, continuous monitoring systems — Gemini 3.5 Flash is the practical production choice. Gemini 3.1 Pro remains the better option for deep, complex reasoning tasks where compute cost is secondary to accuracy.
Why Gemini Is Different from Traditional LLMs
The limitations of post-training modality stitching are rarely discussed plainly enough. Most AI models in production today started as text-only systems. Vision capabilities were added by training a separate image encoder and connecting it to the language model backbone during a later fine-tuning phase. Audio was added the same way — a speech-to-text module upstream, feeding transcribed text into the language model.
This architecture works. But it carries two systemic costs that compound at enterprise scale: latency and contextual loss. Every modality conversion adds processing time. And every conversion discards information that existed in the original signal but has no clean text representation — tone, spatial positioning, temporal continuity, visual-audio synchrony.
Gemini was trained as a single unified neural network across all modalities from day one. Audio features, visual features, code tokens, and natural language tokens all interact during the pre-training phase itself. The result is a model that does not need to "translate" sensory inputs — it simply processes them in the same representational space where it reasons.
Why Google Built Gemini as a Native Multimodal Model
How Traditional AI Models Evolved
The history of deep learning is largely a history of specialisation. Early neural networks were built for one task — vision or language or audio — and optimised hard for that domain. BERT redefined natural language processing in 2018, but it knew nothing about images. ResNet could classify photographs with remarkable accuracy, but it had no concept of syntax or semantics. These systems were powerful precisely because they were narrow.
The multimodal problem emerged once practitioners tried to build applications that reflected reality. Real business problems rarely arrive in a single modality. A customer complaint might come as a voice note, reference a product image, and require querying a text-based knowledge base to resolve. Stitching specialised models together for these workflows meant maintaining multiple inference pipelines, multiple latency budgets, and multiple error modes.
Native Multimodal vs. Add-On Multimodal Systems
The industry's initial response was to create add-on multimodal systems — bolting vision and audio modules onto existing language model cores. This is what is sometimes called the "translation tax." When a model converts audio to text, translates the text into its internal representation, processes it, and converts the output back to audio or action, every step in that chain is an opportunity for latency to compound and nuance to evaporate.
Consider a real-world example: an AI system that handles inbound customer calls. In an add-on architecture, the audio is transcribed to text by one model, the text is parsed for intent by a second, and a response is generated by a third. Three inference calls, three points of failure, three latency contributions. And the transcription step has already discarded the customer's emotional state from the audio signal.
Native multimodal models solve this by eliminating the intermediate conversion steps entirely. All modality signals flow into the same model simultaneously. The system that processes the audio waveform is the same system that reasons about intent and generates a response. This is not merely faster — it produces qualitatively richer outputs because the model never had to discard context to convert between formats.
For native multimodal AI models, the architectural advantage compounds as workflows become more complex. A model that natively sees, hears, and reads simultaneously can execute tasks that add-on systems simply cannot replicate without significant engineering overhead.

Why Google Sees Multimodal AI as the Future
Google's strategic calculus here is specific. The company's core business — Search, Maps, Workspace, YouTube, Android — generates and processes more real-world sensory data than almost any other organisation on the planet. YouTube processes more video hours per day than most broadcasters see in a year. Gmail handles billions of messages containing attachments, voice notes, and structured data. Google Maps processes satellite imagery, street-level photography, and user-uploaded media continuously.
A text-only AI model is architecturally incapable of serving as the intelligence layer for these data streams. A native multimodal model is not just capable — it is necessary. Google's investment in Gemini's native multimodal architecture is as much a product strategy decision as it is a technical one. The model needs to process raw, real-world data feeds — Workspace documents, video feeds, developer repositories — to build reliable, closed-loop software agents capable of executing complex enterprise workflows without constant human intervention.
Understanding Google's Multimodal AI Strategy
Gemini as an AI Layer Across Google
Most AI companies build a product and then seek distribution. Google built distribution first, and Gemini is now becoming the intelligence layer that runs through all of it. This is the core strategic distinction between Google and every other major AI lab.
Gemini is not a destination. It does not primarily exist at gemini.google.com, though that consumer interface exists. Gemini functions as general-purpose AI infrastructure embedded directly into Android, Google Search, Gmail, Google Docs, Google Sheets, Chrome, YouTube, and Google Cloud. Every surface Google owns becomes a potential deployment point for Gemini capabilities, with no additional distribution cost.
Sundar Pichai's I/O 2026 keynote crystallised this clearly: the company is repositioning from an operating system company to an intelligence system company. Every product announcement at the event was, in some sense, a demonstration of Gemini running underneath a familiar Google interface in a new way.
Search and Gemini
Google Search is the most consequential distribution channel in the world for information. The integration of Gemini into Search is not an AI chatbot bolted onto the side of a search engine — it is a structural transformation of what search results are. AI Mode, now the default search experience powered by Gemini 3.5 Flash globally, has surpassed one billion monthly users and is seeing query volume more than double every quarter since launch.
Users submitting complex, multi-step planning queries now receive synthesised AI-generated responses that pull from multiple sources, reason across them, and present a coherent answer — rather than a ranked list of links. Multi-step reasoning queries, travel planning, legal research questions, technical troubleshooting — these now receive structured, cited responses generated directly by Gemini. The implications for how businesses appear in search results, and how information gets surfaced, are significant and actively reshaping the SEO landscape.
Workspace and Gemini
Gemini's integration into Google Docs, Sheets, Gmail, and Calendar operates through Workspace MCP (Model Context Protocol) servers — a standardised protocol that allows AI agents to securely read data, draft content, and execute actions within Google Workspace applications with the same permissions and governance controls as the authorising user.
This is enterprise AI integration done properly. When Gemini drafts a document in Google Docs, it can pull live data from connected Sheets without requiring the user to copy-paste. When it manages calendar scheduling in Gmail, it reads existing commitments and reasons across them. The MCP layer means these integrations are not hard-coded pipelines — they are dynamically queried through a protocol that any authorised AI agent can access. For orchestrated AI workflows within Google Workspace, this is the foundational infrastructure layer that makes genuine enterprise automation possible.
Android and Gemini
On-device AI is a different constraint problem from cloud AI. The model needs to be small enough to run locally on device hardware, fast enough to respond in real time, and capable enough to handle contextually rich tasks without sending every query to a remote server. Gemini Nano serves this role — a lightweight Gemini variant designed for on-device execution, enabling low-latency contextual tasks directly on mobile hardware.
With Android 17, Gemini's on-device capabilities are deeper than a simple text assistant overlay. The system-level model can understand what is on screen, reason about it, and take action — filling forms, navigating apps, managing notifications, and surfacing contextually relevant information without requiring an active internet connection. For enterprise deployments where data sovereignty and latency requirements prohibit constant cloud communication, on-device Gemini represents a meaningful capability.
Cloud and Gemini
Vertex AI remains Google Cloud's enterprise gateway for Gemini. For companies that want to build custom agents, fine-tune models on proprietary data, or deploy managed agentic workflows inside a private cloud environment, Vertex AI provides the infrastructure. Managed agent templates, pre-built integration patterns, enterprise SLAs, VPC integration, and audit logging are all available through the Vertex AI platform.
The Gemini API accessible through Google AI Studio gives developers immediate access to Gemini 3.5 Flash and Gemini 3.1 Pro for building applications. The significant I/O 2026 expansion here was the addition of Managed Agents in the Gemini API — allowing developers to instantiate fully operational AI agents with a single API call, with all execution infrastructure (sandboxed Linux environments, code runtimes, file systems, and browser tools) managed by Google. For enterprise developers exploring long-context reasoning models and custom workflow automation, this is the most consequential infrastructure development of the current cycle.
The Bigger Goal — Is Google Building an AI Operating System?
AI as an Ecosystem
The question sounds dramatic until you map the actual architecture. An operating system is not simply software that runs on hardware — it is a resource management and abstraction layer that allows applications to function without needing to manage hardware directly. It controls access to compute, memory, storage, and I/O, provides security boundaries, and coordinates multiple processes running simultaneously.
Look at what Google is assembling. TPU v6 (Trillium) and TPU 8i provide the custom silicon layer — hardware purpose-built for tensor computation at massive scale. Gemini Omni, the world-model engine announced at I/O 2026, acts as the unified reasoning and media generation core.
Google Antigravity provides the agent orchestration runtime — a system that manages execution environments, schedules tasks, and coordinates multi-agent workflows. Android provides the device-level interface layer. Workspace provides the data and productivity surface. Google Cloud provides the infrastructure perimeter.
Each of these components has an analogy in traditional operating system architecture. Taken together, they describe something that functions like an AI operating system model — a platform layer that manages AI resource allocation, execution, and orchestration across an entire digital environment. Google has not called it this. But the architectural pattern is undeniable.
Agentic Computing and the Google Antigravity Platform
Google Antigravity 2.0, announced at I/O 2026 on May 19, is the clearest evidence that Google is building a platform, not a product. The original Antigravity launched in November 2025 as an AI-assisted development IDE. Version 2.0 is something categorically different: a five-surface agent orchestration platform comprising a standalone desktop application, an Antigravity CLI (the agy command-line tool), an Antigravity SDK, a Managed Agents API tier inside the Gemini API, and an enterprise deployment path through the Gemini Enterprise Agent Platform on Google Cloud.
The architectural innovation at the core of Antigravity 2.0 is its multi-agent execution model. When a developer or enterprise user describes a complex task, a manager agent analyses it, decomposes it into subtasks, and dispatches parallel subagents to execute each component simultaneously. The entire execution environment — sandboxed Linux instances, code runtimes, file systems, and browser tools — is hosted and managed by Google, provisioned per agent with its own isolated security boundary.
The Managed Agents API makes this accessible to any developer through a standard API call. Instead of building and maintaining your own agent infrastructure — model routing, code execution sandboxes, state management, retry logic — a single POST request to the Gemini API instantiates a fully operational agent. You package your instructions, skills, and tools. Gemini builds and runs the agent. Google Cloud handles the security perimeter and execution management.
For enterprise workflow orchestration, the Gemini Enterprise Agent Platform adds VPC integration, audit logging, and governance controls — the compliance infrastructure that makes agentic AI deployable inside regulated industries. MCP servers, A2A (Agent-to-Agent) protocols, and server-side tools are integrated natively, allowing agents to communicate across organisational boundaries and tool ecosystems.
The Antigravity SDK takes this further, giving developers programmatic control to host agents on their own infrastructure, defining custom behaviours and integration patterns beyond what the desktop or CLI expose.
What the Antigravity 2.0 stack makes possible is genuinely new: enterprise teams can now design complex, multi-step business workflows, express them as agent configurations, and deploy them as managed services — without maintaining the underlying execution infrastructure. That shifts the engineering effort from building AI plumbing to defining business logic.
Persistent AI Assistants and Gemini Spark
Gemini Spark, announced during the I/O 2026 keynote, is Google's first consumer-facing persistent AI agent. It is architecturally distinct from every previous Gemini interface: rather than existing inside a chat window and responding only when prompted, Spark runs as a persistent process on dedicated virtual machines inside Google Cloud — continuously, around the clock, regardless of whether the user's device is powered on.
Sundar Pichai described it directly: "It's your personal AI agent that helps you navigate your digital life, taking action on your behalf and under your direction. It runs on dedicated virtual machines on Google Cloud seamlessly — you don't need to keep your laptop open to make sure it's running."
Powered by Gemini 3.5 Flash and the Antigravity agent framework, Spark is capable of long-horizon task execution. It reads incoming email proactively, flags what needs action, drafts replies before being asked, tracks ongoing tasks across days and weeks, and executes multi-step workflows — scheduling, follow-ups, document preparation, research — with explicit approval required only for high-impact actions like sending emails or making purchases. In enterprise contexts through Gemini Enterprise, Spark connects to custom Workspace connectors including Microsoft SharePoint, OneDrive, ServiceNow, and others, making it genuinely useful across mixed-platform organisations.
As of May 2026, Spark is in closed beta for trusted testers, with broader access beginning for US Google AI Ultra subscribers. The AI Ultra subscription tier was repriced from $250 to $100 per month at I/O 2026.
Ambient Intelligence
The logical endpoint of Google's agentic strategy is AI that does not require prompting at all — systems that monitor your environment, understand your context, and surface relevant actions or information at the moment they become relevant. Google calls this ambient intelligence, and it is already visible in the product roadmap.
Android XR glasses, announced at I/O 2026, are the physical form factor for ambient AI. These are not display devices with AI assistants bolted on. They are AI-first wearables where Gemini observes the physical environment through the lens, understands spatial and contextual signals, and provides real-time assistance — translation, wayfinding, contextual lookup, task reminders — without requiring the user to initiate a query. The AI fades into the background, operating passively rather than demanding attention.
The same principle applies to Gemini's integration in Chrome, IDEs, and the Android operating system. The AI layer observes what you are doing and offers relevant capabilities in context, rather than waiting to be explicitly invoked. For enterprise environments, this shifts AI from a tool employees use to infrastructure that actively participates in the work environment.

Gemini 3.1 vs. ChatGPT vs. Claude
Before the analysis, here is a structured comparison of the three frontier AI platforms across the dimensions that matter most for enterprise and developer adoption:
Dimension | Google Gemini 3.1 Pro / Omni | OpenAI GPT-5.x | Anthropic Claude 4 / Sonnet |
Native Modalities | Text, Audio, Image, Video, Code (Unified Training) | Text, Audio, Image (pipeline-optimised) | Text, Image, Code (text-centric focus) |
Context Window | 1 Million tokens (state of the art) | 128,000 tokens | 200,000 tokens |
Agentic Infrastructure | Google Antigravity & Managed Sandbox APIs | Assistants API / ChatGPT Agent | Claude Managed Agents, Computer Use, MCP |
Ecosystem Depth | Embedded in Android, Workspace, GCP, Chrome | Standalone API, Microsoft Azure integration | Standalone API, AWS Bedrock, Claude Code |
Speed Profile | Gemini 3.5 Flash: ~4x faster than frontier rivals | Competitive at standard tiers | Competitive at standard tiers |
Pricing Position | Flash: sub-frontier cost; Pro: premium tier | Premium-range pricing | Premium-range pricing |
Deep-Dive Analysis
Reasoning
Gemini 3.1 Pro's "high-thinking mode" activates extended chain-of-thought processing before output generation, producing measurably stronger results on multi-step logical problems. The Gemini 3 lineage — from which 3.1 Pro derives — demonstrated strong performance on GPQA Diamond, a graduate-level science reasoning benchmark, and SimpleBench, which tests common-sense reasoning chains. These benchmarks are meaningful because they test the kinds of reasoning required for real enterprise tasks: multi-step data analysis, legal document interpretation, scientific literature synthesis.
OpenAI's GPT-5.x series brings its own extended reasoning modes, and performance at the frontier between these models is genuinely close. Claude 4 from Anthropic has demonstrated exceptional multi-step planning capability, particularly for complex document tasks and extended coding sessions. The honest comparative position is that all three models perform at near-equivalent quality on isolated reasoning tasks — the differentiation in practice comes from context window size, ecosystem integration, and agentic infrastructure.
Coding
SWE-bench Verified has become the industry's most respected real-world coding benchmark. Gemini 3.5 Flash performs strongly at this benchmark, and its integration with Antigravity's code execution sandboxes means the model does not just generate code — it executes it, validates it, iterates on failures, and returns a working solution. This is qualitatively different from models that generate code in a text window and leave execution to the developer.
Claude's strength in coding is well established. Claude Code and Claude Managed Agents provide a strong developer experience, with Computer Use enabling the model to interact with actual desktop environments — a meaningful capability for test automation, UI interaction, and complex debugging workflows. OpenAI's GPT-5.3-Codex, released in February 2026, is purpose-built for code generation with a focus on repository-level search and terminal command execution.
For enterprise engineering teams, the critical variable is not which model scores highest on a benchmark on a given day — it is which platform's tooling fits most naturally into the existing development workflow. Antigravity 2.0's multi-agent parallel execution is genuinely novel for tasks that benefit from decomposition and parallel subagent work.
Context Handling
This is where Gemini's advantage is clearest and most durable. Gemini 3.1 Pro's 1-million-token context window is unmatched among production frontier models. OpenAI's current 128,000-token context and Anthropic's 200,000-token context are both significant, but neither can hold an entire enterprise codebase, a full legal document archive, or hours of video footage in a single inference call. Competitors address this gap through retrieval-augmented generation (RAG) — building retrieval pipelines that fetch relevant chunks of large datasets and insert them into smaller context windows.
RAG works. But it introduces engineering complexity, retrieval latency, and the risk of missing relevant context that is not surfaced by the retrieval step. For enterprises where comprehensive context matters — compliance review, large-scale code migration, longitudinal data analysis — Gemini 3.1 Pro's native context capacity is a meaningful structural advantage.
Enterprise Workflows
Vertex AI's managed agent architectures are enterprise-ready in a way that Anthropic's developer-centric tools are still building toward. VPC integration, audit logging, enterprise SLAs, and governance controls are available now on Google Cloud. Anthropic's Claude Managed Agents reached public beta in April 2026, and the Claude Cowork desktop agent reached general availability on April 9, 2026 — meaningful progress, but the enterprise compliance infrastructure is still maturing. OpenAI's Azure integration gives it enterprise credibility in Microsoft-centric organisations, but the depth of Google's native integration across its own product ecosystem is structurally different from a third-party cloud partnership.
Real Business Applications of Gemini 3.1
Developers and Engineering Teams
The most transformative application of Gemini 3.1 Pro in software engineering is large-scale codebase migration. Enterprises maintaining legacy COBOL or Java monolith systems face a technically brutal problem: the codebase is too large and interdependent for any engineer to hold in full context, making confident refactoring nearly impossible without extensive testing at every step.
Gemini 3.1 Pro changes this calculus. With a million-token context window, an engineering team can ingest the entirety of a legacy codebase in a single prompt, ask the model to map all external dependencies, identify the highest-risk refactoring paths, and generate a migration plan to modern microservices architecture. This is not hypothetical — it is a workflow that enterprise teams are executing today on Google Cloud. The model can then assist with incremental migration, generating modern service implementations while maintaining awareness of the legacy interfaces they must replace.
Marketing and Creative Teams
Gemini Omni, the world-model engine announced at I/O 2026, changes the economics of content production. The model accepts any combination of text, images, audio, and video as input and produces video output — natively, without routing through separate specialised pipelines. A marketing team with a written campaign brief can submit it alongside brand assets and reference footage, and Gemini Omni generates short video segments with synchronised audio, adhering to the visual identity of the brief.
The first variant, Gemini Omni Flash, replaces Google's previous Veo model in the Gemini app and is already available in YouTube Shorts Remix, Google Flow, and to AI Ultra subscribers. Character consistency across scenes — maintaining the same visual identity and voice throughout a generated video — is specifically improved in Omni. For teams producing localised campaign variants or high-volume content series, this capability compresses production timelines meaningfully.
Research and Data Science Teams
NotebookLM, Google's AI-powered research tool, provides one of the most immediately practical demonstrations of Gemini's long-context capabilities for research workflows. Research teams can submit multi-hour clinical audio recordings, historical PDF archives, scientific papers, and structured datasets simultaneously, then query across all of them in a single session.
For clinical research teams reviewing hours of patient interview recordings, Gemini's native audio processing — which captures tone, hesitation, and emotional context, not just transcribed words — produces richer analytical output than transcript-based analysis. For data science teams working with large datasets and historical reports, the ability to reason across the full dataset in context, rather than sampling and retrieving, reduces the risk of missing cross-document patterns.
Customer Support and Enterprise Automation
The Antigravity Managed Agents API makes it practical to build end-to-end customer workflow automation without maintaining complex agent infrastructure internally. A real-world example: an enterprise customer support operation needs to handle inbound refund requests, validate them against the order management system, call external payment APIs to process the return, and send a confirmation email with appropriate context.
In a traditional implementation, this requires integrating multiple systems, building a coordination layer, handling error states and retries, and maintaining the entire pipeline. With Antigravity Managed Agents, the workflow is expressed as an agent configuration — instructions, tools, and MCP server connections — submitted via API. The agent executes the multi-step workflow inside a secure, sandboxed environment on Google Cloud, calling external APIs, managing state across steps, and handling retries automatically. The engineering effort shifts from building infrastructure to defining business logic.
What Businesses Should Know Before Adopting Gemini
Key Strengths
Gemini 3.1 Pro's primary competitive strength is the combination of native multimodal processing and massive context capacity. No other production frontier model handles raw audio, video, and full codebase ingestion in a single inference call. For enterprises dealing with heterogeneous data sources — documents, recordings, images, code — this eliminates the need to build and maintain separate preprocessing pipelines for each modality.
The Google Cloud security perimeter is a second meaningful advantage. Enterprise deployments on Vertex AI run within established compliance frameworks, with data isolation, audit logging, and access controls that meet the requirements of regulated industries. Google's infrastructure at TPU scale also means latency and throughput performance for high-volume workloads is exceptionally well-optimised. The depth of Gemini's integration across Search, Workspace, Android, and Chrome means enterprises already running on Google's productivity stack can activate AI capabilities without significant new infrastructure investment.
Limitations and Technical Risks
Hallucination remains a structural limitation of all current frontier models, including Gemini 3.1 Pro. The model is particularly susceptible on highly specific, edge-case reasoning steps — rare technical specifications, obscure regulatory details, specialised domain knowledge that was underrepresented in training data. The "deep thinking" mode, while significantly improving reasoning accuracy on complex tasks, also introduces latency trade-offs. Tasks that require extended chain-of-thought processing may take longer than teams accustomed to faster, simpler completions expect.
The sheer breadth of Google's I/O 2026 announcements also means that some capabilities — particularly in Antigravity 2.0 and Gemini Spark — are in early beta or limited preview. Documentation has not uniformly kept pace with the rate of product development, which means enterprises building on bleeding-edge features should budget engineering time for gaps and changes.
Cost, Privacy, and Vendor Lock-In
Total cost of ownership (TCO) analysis for Gemini deployments requires distinguishing between the model tiers. Gemini 3.5 Flash is the high-volume, cost-efficient choice: at roughly half the per-token cost of comparable frontier models and four times the throughput speed, it is the right default for document processing pipelines, automated workflows, and high-frequency API calls. Gemini 3.1 Pro is the appropriate choice for deep reasoning tasks, complex code analysis, and long-context synthesis — tasks where accuracy is more valuable than throughput speed.
For enterprises processing extreme token volumes, Google publicly demonstrated the arithmetic at I/O 2026: shifting 80% of a trillion-token-per-day workload from frontier-priced models to Gemini 3.5 Flash generates over a billion dollars in annual savings. The numbers are less dramatic at smaller scale but the proportional logic holds.
Data privacy is the critical due diligence question for any enterprise Gemini deployment. The key architectural distinction is between the consumer Gemini app and Vertex AI enterprise deployments. Data submitted to consumer Gemini interfaces may be used to improve Google's base models. Data processed through Vertex AI enterprise configurations operates under Google Cloud's data processing agreements — corporate data is not used to train base public models, and customers maintain ownership of their data. Enterprises must specifically ensure they are routing production workloads through Vertex AI, not the public Gemini API without appropriate enterprise agreements in place.
Vendor lock-in is a legitimate concern. Building deeply integrated workflows on Antigravity, Workspace MCP, and Vertex AI creates structural dependencies on Google's infrastructure. The MCP (Model Context Protocol) standard — originally developed by Anthropic and now adopted natively by Google — mitigates some of this risk for integrations, since MCP-compatible tools and servers should function across multiple agent platforms. But the Antigravity SDK, Workspace deep integrations, and Google Cloud-specific governance features will not transfer cleanly to alternative platforms. Enterprises should enter Google's agentic ecosystem with a clear awareness of this trade-off.
How Gemini Could Change AI Search and Content Discovery
Conversational Search and AI-Generated Answers
Google Search's AI Mode is no longer a feature layered on top of traditional search — it is the default search experience globally, powered by Gemini 3.5 Flash, with over a billion monthly users and query volume more than doubling every quarter. The experience is structurally different from the blue-link model that defined the previous two decades of web search.
Users submitting complex queries receive synthesised, cited responses generated by Gemini — answers that pull from multiple web sources, reason across them, and present a structured response. Multi-step planning queries, research questions, technical troubleshooting, and comparative analysis queries all receive AI-generated answers rather than ranked lists of links. Search is evolving into an answer engine first — a system designed to resolve queries rather than route users to other destinations.
The implications are significant for any business that relies on organic search traffic to attract customers or distribute information. A query that previously sent users to your content now receives an AI-generated answer citing your content — but the user may not visit your page at all.
The Downstream Impact on Web Publishers and SEO
Traditional SEO optimised for ranking signals: domain authority, backlink profiles, keyword density, page speed, structured data. These signals influenced where your page appeared in a list of blue links. That optimisation model is increasingly incomplete in an AI Mode-dominated search environment.
Answer Engine Optimisation (AEO) is the emerging discipline that addresses this shift. When Gemini generates a response to a search query, it draws from web content that is structured for AI retrieval — content that directly answers specific questions, uses clear entity relationships, maintains topical authority on specific domains, and formats information in ways that AI systems can extract and synthesise cleanly.
Publishers and content teams that are not actively optimising for conversational search and AI retrieval are watching organic traffic decline on informational queries. The adjustment is not a full replacement of traditional SEO — domain authority and content quality still matter. But the optimisation target has changed. Being the best source of an answer that Gemini cites, rather than the highest-ranking link on a search results page, is the emerging metric. Structuring content with clear questions, direct answers, semantic entity relationships, and high factual density is the difference between appearing in AI-generated responses and being invisible to a billion monthly users.
Future Predictions for Google's AI Roadmap
The Shift Toward Fully Autonomous Agents
The Antigravity SDK and Managed Agents API have laid the technical foundation for something that is not yet visible in production but is clearly the direction of travel: enterprise agent fleets. Today, businesses deploy individual agents for specific workflows — a customer support agent, a code review agent, a document processing agent. Each operates in relative isolation, handling its defined scope.
The trajectory of the Antigravity platform points toward multi-agent orchestration at organisational scale — fleets of specialised agents that communicate with one another through the A2A (Agent-to-Agent) protocol, coordinating across business functions without human intermediaries at each handoff. An agent that processes an inbound customer complaint passes a structured output to an inventory agent, which checks stock and passes availability to a fulfilment agent, which initiates a shipment and passes tracking information to a communication agent that notifies the customer. Each agent in the chain is specialised. The coordination layer is automated.
Google's integration of A2A protocol support and MCP server connectivity into the Antigravity platform is precisely the architectural work required to make this kind of enterprise agent orchestration feasible. The companies that begin designing their workflows as agent-composable systems now — rather than monolithic pipelines — will have a structural advantage as this infrastructure matures over the next eighteen to twenty-four months.
Persistent Context Memory and Real-Time Multimodal Interaction
The current Gemini architecture still has a fundamental limitation: it does not continuously learn from interactions. Each session starts from the base model, with context provided by the user or retrieved from connected data sources. Gemini Spark's persistent cloud VM architecture is the first step toward dissolving this boundary — the agent maintains state across sessions and learns user preferences over time, but the base model itself remains static between updates.
The next architectural frontier is persistent context memory: models that continuously integrate learnings from environment interactions without requiring explicit retraining or forgetting historical patterns across sessions. Combined with real-time multimodal processing — where the AI is not invoked for individual queries but continuously observes a live environment, making context-aware suggestions and executing delegated tasks as conditions change — this represents the end state of ambient intelligence as a practical operating model.
The hardware layer is already being prepared. TPU 8i, announced at I/O 2026, provides the compute foundation for inference at the scale required for always-on, persistent context architectures. The software architectures that will run on this hardware are being designed in parallel. Businesses that understand where this is heading can begin designing their data governance, workflow structures, and integration architectures to be ready when persistent, real-time agentic systems become production-ready.
Conclusion — Gemini 3.1 and Google's Multimodal AI Strategy Could Redefine Computing
Gemini 3.1 and Google's Multimodal AI Strategy represent something more consequential than a model release cycle. They represent a structural shift in how enterprise AI is architected — from tools that respond to queries, to systems that observe, reason, and act continuously across every surface where work happens.
The core elements of this shift are now in production: a natively multimodal reasoning engine in Gemini 3.1 Pro and 3.5 Flash; a world-model creative engine in Gemini Omni; a persistent personal agent in Gemini Spark; a five-surface agentic development platform in Antigravity 2.0; and MCP-based integrations that connect AI agents to live Workspace data, Google Cloud services, and third-party enterprise tools.
What distinguishes Google's position from every other AI company is not any single model capability. It is the platform depth. Gemini runs inside Search, Workspace, Android, Chrome, Cloud, and YouTube simultaneously. The intelligence layer does not need to be integrated — it is already there, waiting to be activated. For enterprises, this is both the opportunity and the strategic question: how to activate these capabilities intelligently, within appropriate governance frameworks, and in ways that generate compound value rather than isolated demonstrations.
At FourfoldAI, we specialise in exactly this transition. We help enterprises design and implement custom agentic systems — leveraging Gemini's multimodal infrastructure, Antigravity's managed agent platform, and Vertex AI's enterprise governance layer to build workflows that run autonomously, scale reliably, and integrate securely with existing business operations. If your organisation is evaluating where agentic AI fits in your technology roadmap, we'd like to help you think through it.
Explore how FourfoldAI designs and deploys enterprise-grade AI systems at fourfoldai.com.
Frequently Asked Questions
What is Gemini 3.1?
Gemini 3.1 Pro is a natively multimodal large language model developed by Google DeepMind, released on February 19, 2026. It is designed to process text, audio, images, video, and code simultaneously within a single unified neural network — not by converting each modality to text first, but by reasoning across all formats natively. Key capabilities include:
A 1-million-token context window for processing entire codebases, video recordings, and large document archives in a single prompt
High-level reasoning performance on complex multi-step tasks via "deep thinking" mode
Native audio processing that captures emotional tone and inflection, not just transcribed words
Strong code generation and repository-level engineering assistance
Deep integration with Google Cloud, Workspace, Android, and the Antigravity agent platform
Gemini 3.1 Pro is the deep-reasoning model in Google's current lineup. Gemini 3.5 Flash, announced at Google I/O 2026, is the faster, more cost-efficient model designed for high-volume agentic task execution.
How is Gemini different from ChatGPT?
The differences operate at multiple levels — architecture, context capacity, and ecosystem integration.
Architecture: Gemini is trained natively on text, audio, image, video, and code simultaneously. ChatGPT (GPT-5.x series) processes audio and images through pipeline-optimised modules added to a text-centric core. Gemini does not need to convert modalities before reasoning; GPT models still carry some "translation tax" for non-text inputs.
Context window: Gemini 3.1 Pro supports 1 million tokens. Current GPT-5.x models support 128,000 tokens. For enterprise tasks requiring full codebase or document archive analysis, this gap is significant.
Agentic infrastructure: Google Antigravity 2.0 provides a full multi-agent orchestration platform with managed execution sandboxes. OpenAI offers the Assistants API and the ChatGPT Agent, which are capable but lack the same depth of cloud-managed execution infrastructure.
Ecosystem: Gemini is embedded natively inside Search, Workspace, Android, Chrome, and Google Cloud. OpenAI's distribution runs primarily through the API and Azure partnership. For organisations already operating in Google's ecosystem, the integration depth of Gemini is structurally different.
Why is Google investing heavily in multimodal AI?
Google's investment in multimodal AI is driven by a specific strategic reality: its core products generate and process massive volumes of non-text data. YouTube processes more video than most broadcasters see annually. Gmail handles billions of messages with attachments and voice notes. Google Maps processes satellite imagery and street-level photography continuously. A text-only AI model is architecturally incapable of serving as the intelligence layer for these data streams.
Additionally, real-world enterprise workflows rarely arrive in a single modality. A customer complaint may come as a voice note, reference a product image, and require querying a structured database to resolve. Multimodal AI reduces the engineering overhead of handling these heterogeneous inputs. Google's investment is both a product necessity — its own services require it — and a competitive positioning decision for enterprise customers who need the same capability.
Can Gemini understand video and audio natively?
Yes. This is one of Gemini's core architectural distinctions. Gemini 3.1 Pro processes video and audio natively — not by transcribing audio to text or extracting keyframes from video first, but by reading the raw audio waveform and full video sequence within its neural architecture.
For audio, this means the model captures tone, inflection, emotional state, and speech rhythm — contextual signals that transcription loses. For video, Gemini's 1-million-token context window allows processing of hour-long video recordings in a single prompt, tracking narrative continuity and context across the full duration.
Gemini Omni, announced at Google I/O 2026, extends this further — it not only processes video and audio natively but generates video output with synchronised audio from any combination of text, image, or video inputs. It replaces Google's previous Veo model in the Gemini app and represents a shift toward unified any-to-any media generation.
Is Gemini better for enterprise businesses?
Gemini has structural advantages for enterprise adoption that go beyond model capability scores. The relevant enterprise-specific strengths are:
Vertex AI enterprise infrastructure: VPC integration, audit logging, enterprise SLAs, and compliance controls for regulated industries
Workspace integration via MCP: Agents can read and act within Gmail, Docs, Sheets, Calendar, and Drive without building custom integrations from scratch
Antigravity Managed Agents: Full multi-agent workflow orchestration with secure, sandboxed execution environments managed by Google Cloud
Gemini Spark for Gemini Enterprise: A 24/7 background agent that works across Workspace, custom connectors, and third-party tools
Data governance: Enterprise Vertex AI deployments ensure corporate data is not used to train public base models
For Microsoft-centric organisations, OpenAI's Azure integration is a legitimate alternative. For organisations already running on Google's productivity stack, Gemini's native integration depth provides a faster path to production AI deployment.
Can Gemini replace Google Assistant?
Google Assistant is already being replaced by Gemini across Android devices and Google's consumer products. The transition has been progressive since 2024, with Gemini becoming the default assistant on Android. Gemini Spark represents the next phase of this replacement — a persistent 24/7 agent that goes significantly beyond what Google Assistant could do.
The functional difference is substantial. Google Assistant answered questions and executed simple commands. Gemini Spark executes multi-step workflows autonomously, maintains persistent state across days and weeks, proactively monitors your email and calendar for action items, and integrates with third-party enterprise tools via MCP connectors. The assistant model — reactive, session-bound, query-driven — is being retired in favour of the agent model — proactive, persistent, workflow-driven.
What industries benefit most from Gemini's architecture?
Gemini's native multimodal processing and long-context reasoning create specific advantages across several industries:
Legal and compliance: Full contract archive analysis, regulatory document review, multi-document synthesis without RAG chunking limitations
Healthcare and clinical research: Native audio processing of patient interview recordings, clinical trial document analysis, multi-modal medical record review
Software engineering: Full codebase ingestion for legacy migration, cross-file dependency analysis, automated code review at scale
Financial services: Document analysis across large report archives, automated compliance monitoring, multi-step financial workflow automation via Antigravity agents
Marketing and creative: Video campaign production via Gemini Omni, automated content localisation, multimodal brief-to-production workflows
Customer support: End-to-end workflow automation via Managed Agents, native audio sentiment analysis for call centre operations
Does Gemini work with Google Workspace MCP?
Yes. Google Workspace MCP servers are official Model Context Protocol implementations maintained by Google, allowing AI agents to securely read data and take actions within Gmail, Google Drive, Google Docs, Google Sheets, Google Calendar, and Google Chat. These servers:
Inherit the same permissions and data governance controls as the authorising user
Provide standardised read and write access for AI agents without requiring custom API integrations
Are compatible with multiple AI clients including Gemini CLI, Claude, and other MCP-compatible tools
Are documented at Google's official developer documentation and available for enterprise configuration through Google Cloud projects
For enterprise deployments, an additional data loss prevention (DLP) layer is recommended to inspect and govern what data from Workspace is passed into AI model context windows before reaching the model. Google Cloud's enterprise configurations provide the appropriate governance controls for regulated environments.
Is Google's AI strategy fundamentally different from OpenAI's?
The difference is structural, not merely a matter of degree. OpenAI's strategy is product-first — build powerful models, deploy them through a consumer product (ChatGPT) and a developer API, and distribute them through a cloud partnership (Azure). The go-to-market is a standalone AI product that enterprises integrate into their existing systems.
Google's strategy is ecosystem-first — embed AI infrastructure into every product it already owns and distribute AI capabilities through existing user relationships at zero additional acquisition cost. Gemini does not need to convince users to try a new product. It becomes available to Search's billion-plus monthly users, to every Android user, to every Gmail and Docs user — automatically, through products they already use daily.
This creates a fundamentally different competitive dynamic. OpenAI competes for enterprise contracts and developer adoption. Google competes by making AI the default capability of the most widely distributed digital ecosystem in the world. The risks are also different: Google's strategy is constrained by regulatory scrutiny of its ecosystem dominance; OpenAI's strategy is constrained by distribution costs and the need to win customer trust from scratch.
Could Gemini eventually become an AI operating system?
The architectural evidence points in that direction, though Google has not used that framing explicitly. An operating system manages resources, coordinates processes, provides security boundaries, and abstracts hardware complexity for applications. Looking at what Google is building: TPU 8i provides custom compute silicon optimised for AI inference at scale; Gemini Omni provides the unified reasoning and media generation core; Google Antigravity provides the agent orchestration runtime that manages execution environments and coordinates multi-agent workflows; Android, Workspace, Chrome, and Search provide the interface layers.
Each of these components has a functional analogy in traditional operating system architecture. Taken together, they describe something that functions like an AI operating system model — a platform that manages AI resource allocation, execution environments, and inter-agent coordination across an organisation's entire digital environment. Whether Google calls it that or not, the architectural pattern is becoming clear. The more interesting question for enterprises is: what are the implications of a world where AI infrastructure is as invisible and ubiquitous as the operating systems we already depend on?
References and Sources
This article is backed by authoritative sources, official product documentation, and verified announcements. All claims reflect information available as of May 2026.
Google Blog — I/O 2026: Welcome to the Agentic Gemini Era (May 2026) blog.google — Sundar Pichai I/O 2026 Keynote
Google Blog — 100 Things We Announced at Google I/O 2026 blog.google — I/O 2026 All Announcements
Google Cloud Blog — I/O '26 News for Agent Developers on Google Cloud cloud.google.com — IO26 Agent Developer News
Google Cloud Blog — Innovations from Google I/O 26 on Google Cloud cloud.google.com — IO26 Innovations
Google for Developers — Configure the Google Workspace MCP Servers developers.google.com — Workspace MCP
Google Cloud Documentation — Google Cloud MCP Servers Overview docs.cloud.google.com — MCP Overview
Google GitHub — Google MCP Repository github.com/google/mcp
TechCrunch — Google Introduces Gemini Spark at I/O 2026 techcrunch.com — Gemini Spark
MarkTechPost — Google Launches Antigravity 2.0 at I/O 2026 marktechpost.com — Antigravity 2.0
Wikipedia — Gemini 3 (AI) en.wikipedia.org — Gemini 3
Disclaimer
The information provided in this article is for general educational and informational purposes only. While FourfoldAI strives to ensure the accuracy and timeliness of all content, the AI industry evolves rapidly and specific product capabilities, pricing, availability, and benchmark results may have changed since publication. This article should not be construed as professional or technical advice for specific business implementation decisions.
For the full FourfoldAI content disclaimer, including terms of use, liability limitations, and editorial standards, please visit: fourfoldai.com/disclaimer
About the Author
Muizz Shaikh is an AI enthusiast and digital technology professional at FourfoldAI. He is passionate about exploring AI tools, industry trends, and practical applications of emerging technologies. Through FourfoldAI, Muizz contributes to simplifying artificial intelligence for businesses and learners. Connect with him on LinkedIn: linkedin.com/in/muizz-shaikh-45b449403/
© 2026 FourfoldAI. All rights reserved. Published at fourfoldai.com



Comments