
SLM vs LLM: Architecting the Modern Enterprise AI Stack
- Shaikhmuizz javed
- 3 days ago
- 19 min read

By ShaikhMuizz | FourFoldai
Why the SLM vs LLM Debate is Shaping Enterprise AI in 2026
Your engineering team just received a quote from an LLM API provider: $28 per million output tokens for the frontier model your product currently depends on. At current request volume, that's a five-figure monthly bill — for a pipeline that classifies support tickets and extracts order IDs. Something is clearly wrong with the architecture.
This is the friction point at the heart of the SLM vs LLM debate. It isn't a theoretical research discussion about which architecture is more sophisticated. It's a very real, very practical infrastructure question that engineering and product teams across industries are reckoning with right now.
For the past three years, the dominant instinct in enterprise AI was simple: use the biggest model available, route everything through a cloud API, and ship. That instinct made sense when model quality gaps were enormous and smaller alternatives couldn't reliably follow instructions or handle structured outputs. But the calculus has shifted. The quality gap between frontier LLMs and purpose-built smaller models has narrowed considerably on targeted tasks — and the cost and infrastructure differences have only grown.

The Limits of Monolithic AI Systems
Routing every task — from "classify this email as spam or not" to "summarize this legal contract" to "write a technical blog post" — through the same trillion-parameter model is economically unsustainable at scale. A call center processing 10 million interactions per month doesn't need GPT-4 class reasoning to categorize a customer complaint. It needs speed, consistency, and low cost per call.
There's also a performance problem hiding inside monolithic reliance on large models. General-purpose LLMs are trained to handle everything — which means they're not always optimized for anything specific. A domain-specialized smaller model, fine-tuned on a well-curated corpus of medical notes or financial disclosures, can outperform a generalist LLM on its home turf. The Diabetica-7B model, a diabetes-domain SLM, reportedly achieved 87.2% accuracy on domain-specific benchmarks — surpassing both GPT-4 and Claude 3.5 on that narrow task.
The Rise of Edge and On-Premises Computing
Data sovereignty is no longer a niche compliance concern. It's a boardroom agenda item. Healthcare providers can't send patient records to a third-party API endpoint. Financial institutions face strict regulations around where data is processed and stored. Government agencies operate with air-gapped infrastructure requirements.
These constraints are forcing a fundamental rethink of where intelligence lives. Processing must move closer to the source — to the enterprise's own servers, to the edge device, to the factory floor sensor, or to the mobile application running on a healthcare worker's tablet. That physical constraint eliminates most frontier LLMs from the equation entirely. What's left is a very strong argument for SLMs.
Defining the Contenders: Technical Differences Between SLMs and LLMs
What Defines a Small Language Model (SLM)?
An SLM is typically characterized by a parameter count under 15 billion, though the meaningful performance threshold for practical production SLMs has settled in the 1B to 8B range for most enterprise use cases. What separates modern SLMs from earlier "small models" isn't just the reduced size — it's how they're trained.
Models like Microsoft Phi-4 (3.8B parameters) and Meta Llama 3.2 (available in 1B and 3B variants) are trained on curated, high-quality datasets rather than raw internet crawls. Microsoft trained Phi-4 primarily on synthetic data — curated reasoning exercises, verified code, and academic textbooks — achieving a knowledge density that allows it to match GPT-4o on structured extraction benchmarks and outperform it on MATH and GPQA (graduate-level reasoning). That's a 3.8 billion parameter model beating a model orders of magnitude larger on specific tasks.
Google Gemma 2 (9B) delivers strong benchmark scores across MMLU, HellaSwag, and GSM8K, with commercial licensing that makes it viable for enterprise deployment. Mistral 7B remains the open-weight community's go-to for fine-tuning experimentation. Meta Llama 3.2 at 1B and 3B is purpose-built for mobile and edge, running at 20–30 tokens per second on iPhone 12+ hardware with 4-bit quantization — the entire model fitting inside 650 MB of RAM.
The architecture under the hood is recognizable — transformer blocks, attention mechanisms, contextual embeddings — but the design philosophy emphasizes inference efficiency. Fewer layers, smaller hidden dimensions, and optimized attention patterns mean faster Time-To-First-Token (TTFT) and lower power consumption per generation step.
What Defines a Large Language Model (LLM)?
LLMs operate at a different scale entirely. The frontier models — OpenAI GPT-5, Anthropic Claude Opus 4.6, and Google Gemini 3.1 Pro — have parameter counts ranging from hundreds of billions to over a trillion effective parameters in Mixture-of-Experts (MoE) architectures.
MoE designs are particularly important to understand. A model like GPT-4 doesn't activate all its parameters for every token. Instead, a routing mechanism selects a subset of "expert" subnetworks for each forward pass. This allows a model to have an enormous total parameter count while keeping per-token inference compute manageable — though the full model weight still needs to reside in memory, which translates to significant VRAM requirements and infrastructure costs.
The value proposition of LLMs is parametric memory. A model trained on hundreds of billions of tokens from diverse text corpora builds a broad internal representation of the world — science, law, medicine, software, history, multiple languages — without needing that information explicitly fed into its context window. For open-ended synthesis, multi-step strategic reasoning, and tasks where the domain is undefined at query time, this breadth is genuinely irreplaceable.
What is the difference between an SLM and an LLM? An SLM is a highly optimized model with fewer parameters (typically under 15 billion) designed to run on limited hardware or edge devices, excelling at specific, targeted tasks. An LLM is a massive foundation model (often hundreds of billions of parameters) trained to handle broad, generalized reasoning across diverse domains but requiring high-compute cloud infrastructure to operate. The key trade-off is generalization capacity versus operational efficiency: LLMs know more about everything; SLMs do specific things faster, cheaper, and with greater data privacy.

The Direct Comparison: SLM vs LLM Performance, Costs, and Efficiency
Latency and Throughput Comparison
Time-To-First-Token (TTFT) is the metric that decides whether an AI feature feels responsive or broken to end users. For real-time applications — customer-facing chatbots, voice assistants, in-app recommendations — anything over 800ms feels like lag.
A locally hosted Mistral 7B at Q4 quantization on an NVIDIA A10G GPU generates a first token in roughly 40–80ms under low concurrency. Compare that to a frontier API call, which must travel over the internet, queue behind other requests, and return a response — often clocking 300ms to over 1 second TTFT before a single token appears, depending on load and geography.
For high-volume transactional systems processing thousands of requests per minute, the math compounds. SLMs running on private infrastructure can be horizontally scaled at predictable costs. A frontier LLM API introduces variable latency tied to external service congestion, rate limits, and network hops. That unpredictability is a serious engineering liability in any latency-sensitive production system.
For code completion tools, real-time document analysis, and on-device mobile AI, SLMs with sub-100ms TTFT are not just preferable — they're the only viable option.
Compute and Memory Footprints (Quantization Math)
This is where engineering reality diverges sharply from theoretical model comparisons. Understanding the actual memory requirements for local deployment requires knowing the precision-parameter relationship.
The core formula: Parameters × Bytes per parameter = VRAM required for weights.
At FP16 precision (2 bytes per parameter), an 8B model requires 16 GB of VRAM for weights alone. With runtime overhead and KV cache for a reasonable context length, peak VRAM sits at 18–20 GB — already exceeding most consumer GPUs and mid-range enterprise workstations.
Quantization changes the equation. INT4 (4-bit) reduces each parameter to 0.5 bytes. That same 8B model, quantized to Q4_K_M format, drops to approximately 4.5–5.5 GB of VRAM — fitting comfortably on an 8 GB NVIDIA RTX 3070 or the unified memory of an Apple M2 laptop. Quality loss on general benchmarks is minimal: INT4 quantized models typically retain 95–98% of FP16 accuracy on standard tasks, with more noticeable degradation only on complex multi-step reasoning.
The math for larger models: a 70B parameter model at FP16 requires 140 GB of VRAM — impossible on a single consumer GPU. At INT4, it drops to approximately 35–40 GB, which still requires multi-GPU enterprise hardware, but now becomes feasible on a dual-A100 server. For most SLMs in the 3B–8B range, INT4 quantization makes local deployment viable on commodity enterprise workstations worth $1,500–$4,000.
Direct API Costs vs. Private Hosting FinOps
Token-based pricing has compressed significantly across the industry in 2025–2026. But the absolute numbers still matter at volume. Claude Opus 4.6 from Anthropic costs $5 per million input tokens and $25 per million output tokens. GPT-5 sits at roughly $10/$30 per million tokens (input/output). These are genuinely frontier-quality models — but even at these prices, high-volume enterprise deployments hit serious monthly bills.
For context: a deployment processing 5 million output tokens per day (a modest volume for a production assistant or document processing pipeline) would cost $125/day or ~$3,750/month at Claude Opus pricing. Scale that to 50 million tokens per day — entirely reasonable for an enterprise platform — and the monthly API bill reaches $37,500 for output tokens alone.
Private hosting of open-weight SLMs shifts the cost structure entirely. A single NVIDIA A10G GPU ($1,500–$3,000 for cloud leasing or $5,000–$8,000 purchased) can serve Mistral 7B at production scale. Annual cloud instance costs for a private SLM serving 10,000 daily queries typically run $500–$2,000 per month — compared to $5,000–$50,000 per month for equivalent LLM API consumption at those volumes.
There's a FinOps consideration on the other side, too. Private hosting carries operational overhead: infrastructure management, model updates, monitoring, and engineering time for deployment pipelines. For teams without MLOps maturity, that overhead can offset the cost savings. The honest answer is that private SLM hosting only makes financial sense beyond a meaningful request-volume threshold — and that threshold is lower than most teams assume.
SLM vs LLM Comparison Table
Metric | Small Language Model (SLM) | Large Language Model (LLM) | Structural Trade-off |
Parameter Range | Typically 1B–15B | 70B–1T+ (MoE or dense) | SLM: task-specific depth; LLM: cross-domain breadth |
Typical VRAM Requirements | 2–16 GB (5–6 GB at Q4) | 40 GB–700 GB+ depending on precision | SLM fits consumer hardware; LLM needs datacenter-grade GPU clusters |
Core Strengths | Speed, privacy, fine-tuning, edge deployment | Complex reasoning, multi-domain knowledge, creative synthesis | Operational efficiency vs. generalization power |
Latency Profile | 40–150ms TTFT (local) | 300ms–1.5s TTFT (API, variable) | SLM wins on real-time and high-frequency use cases |
Deployment Model | On-device, private cloud, VPC, edge hardware | SaaS API, dedicated enterprise cloud instance | SLM: data stays internal; LLM: data leaves the network |
Token Costs | ~$0.10–$0.50/1M tokens (hosted API); near-zero (self-hosted) | $1–$30/1M tokens depending on model tier | SLM is 5–20x cheaper at comparable task complexity |
When to Choose an SLM vs LLM for Production Applications
Use Cases Built for Small Language Models (SLMs)
Document classification and entity extraction. A legal firm processing thousands of contracts per week needs reliable extraction of dates, parties, clauses, and obligation types. A fine-tuned 7B SLM on a curated legal corpus will consistently outperform a generalist LLM on this task — with faster throughput, lower cost per document, and zero data leaving company infrastructure.
On-device mobile applications. Apple Intelligence uses a family of on-device models precisely because sending every Siri request to a cloud endpoint introduces unacceptable latency and privacy concerns. Llama 3.2 1B running locally on an iPhone processes voice commands, drafts replies, and performs text summarization without a network connection.
Offline and air-gapped environments. Manufacturing floor automation, military systems, and healthcare devices with network restrictions need intelligence that operates independently. An SLM quantized to run on an NVIDIA Jetson Orin module delivers real-time quality inspection on a semiconductor production line without any cloud dependency.
Local code completion. Developer productivity tools running inside an IDE benefit enormously from sub-100ms TTFT. GitHub Copilot's local inference mode and alternatives like Continue.dev use SLMs precisely for this reason — users perceive responsive code completion as almost magical; a 400ms delay breaks the flow entirely.
Private RAG pipelines. When an enterprise combines an SLM with an internal enterprise vector databases layer, the model can retrieve and reason over proprietary documentation without any of that information ever touching an external API. The SLM handles retrieval-augmented generation locally; sensitive data stays inside the VPC.
Use Cases Requiring Large Language Models (LLMs)
Open-ended creative and strategic synthesis. Writing a detailed product strategy document, generating a multi-chapter technical whitepaper, or brainstorming a complex marketing campaign draws on the deep parametric memory of a frontier LLM. These tasks require connecting disparate concepts across domains — a capability that emerges at scale.
Complex cross-domain logical reasoning. Multi-step inference chains involving science, law, finance, and language simultaneously favor models trained on the breadth of human knowledge. An LLM that can "know" that a legal interpretation depends on a recent regulatory amendment it encountered during training offers something no targeted SLM can replicate without that specific training data.
Multi-language translation at enterprise scale. Frontier models handle nuanced translation across 50+ languages, including low-resource languages with limited training data. Specialized SLMs like Qwen2.5 7B cover 29 languages competently, but for rare language pairs or dialect-sensitive translation, LLM depth remains the safer choice.
Unstructured strategic analysis. Synthesizing a quarterly earnings call, cross-referencing market research with internal sales data, and generating an executive briefing requires the kind of flexible contextual understanding that only a frontier-class model reliably delivers.
The Knowledge Capacity Trap
Here's a limitation of SLMs that enterprise teams routinely underestimate. Smaller models have significantly less parametric memory — the internal "knowledge" baked into their weights during training. An 8B parameter model has simply stored less information about the world than a 200B parameter model trained on the same data.
This creates a predictable failure mode: an SLM deployed as a general-purpose assistant confidently confabulates answers on topics that fall outside its training distribution. It hallucinates dates, invents citations, misremembers regulations.
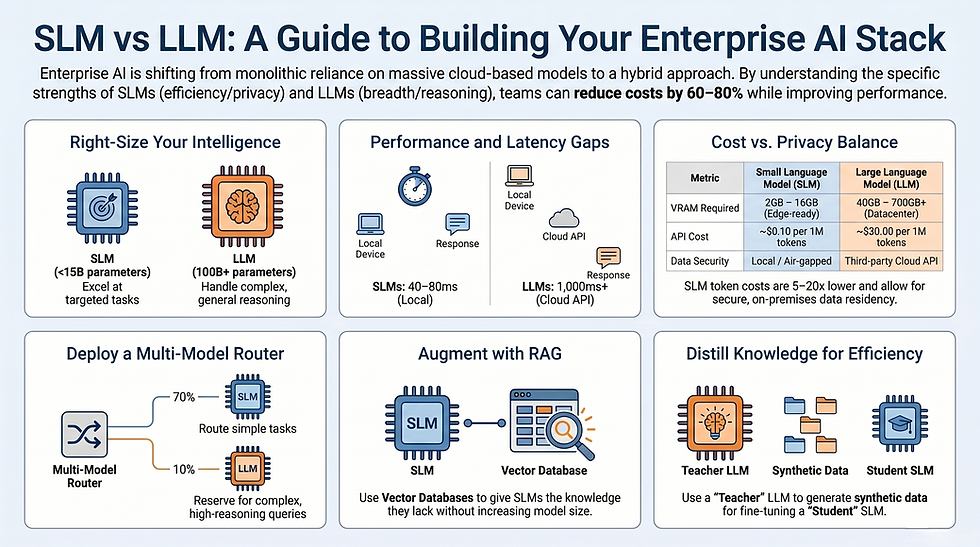
The standard mitigation is Retrieval-Augmented Generation (RAG). By pairing an SLM with a vector search layer — indexed over the enterprise's internal documents, databases, and knowledge bases — the model doesn't need to "remember" facts from its weights. Relevant information is retrieved at query time and fed directly into the prompt. This lets a 7B SLM answer questions about a specific product version released six months after its training cutoff, or reason about a proprietary business process it was never trained on. The SLM provides the reasoning engine; custom AI memory systems provide the knowledge substrate.
Designing a Hybrid Multi-Model Architecture with SLMs and LLMs
The most important insight in this entire comparison: real production systems don't choose one or the other. They use both, intelligently. The SLM vs LLM framing is useful for understanding trade-offs, but it breaks down as an architectural prescription. The most capable and cost-efficient enterprise AI systems in 2026 are hybrid orchestrations.
The Multi-Model Routing Framework
The core idea is deceptively simple: not every query needs the same model. An intelligent routing layer — itself often a lightweight classifier or small model — evaluates incoming requests and directs them to the appropriate inference endpoint.
In practice, a tiered routing architecture might look like:
70% of queries route to a local or low-cost SLM: simple classification, structured extraction, templated generation, FAQ answering, intent detection.
20% of queries route to a mid-tier model (e.g., Claude Sonnet 4.6 at $3/$15 per million tokens): nuanced summarization, moderate-complexity reasoning, multi-turn dialogue.
10% of queries escalate to a frontier model (Claude Opus 4.6, GPT-5): strategic analysis, creative synthesis, multi-domain complex tasks.
Real-world implementations of this pattern have demonstrated 60–80% reductions in average per-query cost compared to routing all traffic through a single premium model. The routing decision doesn't need to be perfect — even coarse-grained complexity estimation produces significant savings.
The routing signal can come from several sources: query length, domain classification, user tier, estimated reasoning depth, or a confidence cascade where the SLM attempts the task first and triggers LLM escalation only when its internal confidence scores fall below a threshold.
Using LLMs as Teacher Models (Knowledge Distillation)
Knowledge distillation — introduced by Hinton et al. in 2015 — is the process of using a larger "teacher" model to train a smaller "student" model. In practice, the teacher LLM generates a rich dataset: worked examples, chain-of-thought reasoning traces, annotated outputs, and calibrated probability distributions over possible answers.
The student SLM trains on this synthetic data, learning not just correct outputs but how to reason toward them. The result is a small model that punches above its parameter count on the specific tasks the teacher was asked to demonstrate.
Microsoft's Phi-4 is a well-documented example of this approach in action. Heavy reliance on synthetic training data — essentially distilled knowledge from larger models — enabled it to match GPT-4o on structured extraction despite being orders of magnitude smaller.
For enterprise teams, this creates a viable pipeline: use Claude Opus or GPT-5 to generate high-quality synthetic training data aligned with your specific workflows, then fine-tune a Mistral 7B or Llama 3.2 on that dataset for internal deployment. The LLM costs are incurred once during data generation; the SLM handles production inference at a fraction of the ongoing cost. RAG distillation techniques have shown this can even work in a black-box fashion — where the enterprise doesn't have access to the teacher model's internals, only its outputs.
SLMs as Specialized Agents in a Federated Network
The next architectural evolution is federated agent networks — multiple domain-specific SLMs operating cooperatively, each responsible for a distinct capability. Think of it as a team of specialists rather than a single generalist.
A financial services platform might run:
A code generation SLM (Codestral 7B) that translates natural language into SQL queries against internal data warehouses.
A document analysis SLM (fine-tuned Phi-4) that extracts structured data from regulatory filings and earnings reports.
A customer communication SLM (fine-tuned Gemma 2) that drafts compliant, tone-appropriate client emails.
An orchestration layer — potentially a slightly larger model or a rules-based router — that decomposes user requests and delegates subtasks to the appropriate specialist.
This architecture is precisely what autonomous AI agent design principles support: specialized competence over generalized adequacy. The network is more capable than any single model because each SLM is optimized for its specific domain rather than compromised to handle everything.
Strategic Trade-offs: Security, Sovereignty, and Adaptability
Enterprise Security Boundaries
Every call to a third-party LLM API carries a data risk. Terms of service for most providers explicitly address how prompt data is used — but the legal text in a vendor contract is cold comfort when a proprietary algorithm, a sensitive customer interaction, or confidential financial projection leaves your network.
On-premises or VPC-hosted SLMs eliminate this attack surface entirely. When the model runs on your hardware, inside your network perimeter, no prompt data traverses an external endpoint. No logs are created on a third-party server. No future model training might inadvertently incorporate proprietary inputs. For industries where data residency isn't optional — banking, defense, healthcare, legal — this is not a preference; it's a hard requirement.
The security calculus also applies to model behavior. A self-hosted SLM can be aligned, audited, and frozen to a known state. A frontier API model may receive silent updates that change its output behavior — a version shift your compliance team had no visibility into.
Customization and Fine-Tuning Overhead
Fine-tuning a 7B parameter SLM on a domain-specific dataset is a tractable engineering task. With Parameter-Efficient Fine-Tuning (PEFT) techniques like LoRA (Low-Rank Adaptation), the trainable parameters drop to a fraction of total model size — enabling fine-tuning runs on a single A100 GPU in hours rather than days.
The fine-tuning process for an SLM is dramatically faster and cheaper than for an LLM. Typical domain adaptation cycles for a 7B model with a curated 10K–50K sample dataset run in 2–8 hours on a single A100, costing $20–$80 in cloud compute. Iteration is fast enough for weekly or even daily retraining as new data accumulates.
Customizing a closed-source frontier LLM is a different problem. Most providers offer fine-tuning through API endpoints at premium pricing, with limited visibility into the fine-tuning process, strict constraints on dataset formats, and no ability to validate the model's internal behavior. Prompt engineering and retrieval augmentation remain the primary customization levers for external LLM APIs — powerful but constrained compared to weight-level adaptation.
Future-Proofing the Enterprise AI Stack
Model generations are turning over every 12–18 months. An enterprise that hardcodes its product around a specific frontier LLM is accepting upgrade risk every time that provider releases a new generation with changed behavior, revised pricing, or deprecated endpoints.
The pragmatic hedge is an abstraction layer — a model-agnostic inference interface that decouples application logic from specific model implementations. Frameworks like LiteLLM, LangChain's model provider abstraction, or custom internal routers allow the underlying model to be swapped — from GPT-4o to Claude Sonnet to a self-hosted Llama — without modifying application code.
This architectural principle applies symmetrically to SLMs. A company deploying Phi-4 today should build its pipelines to accommodate Phi-5 or a successor model when it arrives — likely with better performance at the same or smaller parameter count. Locking deeply into a single model's output format or behavior quirks creates migration debt. Staying model-agnostic doesn't mean staying ignorant of model differences; it means building systems that can absorb model evolution without regression.
Key Takeaways for Evaluating SLM vs LLM Deployments
The SLM vs LLM decision is ultimately an engineering design problem, not a prestige question. Bigger models are not inherently better models for your use case — they're just more expensive and more capable at things you might not need.
Here's how to frame the decision framework:
Choose an SLM when: Your task is narrow and well-defined. Data privacy or residency requirements are non-negotiable. Latency under 200ms is a product requirement. Your request volume makes API costs unsustainable. You need fast iteration cycles on fine-tuning and want full control over model behavior.
Choose an LLM when: The task requires genuine cross-domain reasoning or creative synthesis. The query domain is undefined at design time. Multilingual breadth across 50+ languages is required. Your volume is low enough that per-token pricing is manageable. Building and operating a private inference stack isn't a priority.
Choose both — intelligently routed — when: You're building a product that serves diverse request types at significant scale. The right answer for the majority of the FourfoldAI community is the third option.
Hybrid multi-model orchestration — with SLMs handling the high-volume, latency-sensitive, privacy-critical layer and LLMs handling the complex, open-ended, low-frequency tasks — is the operating standard for well-engineered enterprise AI pipelines. The economics favor it. The security posture favors it. The performance profile favors it.
Building a production AI system around a single monolithic model endpoint is the equivalent of using a freight truck to deliver single envelopes — technically functional, completely inefficient.
Frequently Asked Questions About the SLM vs LLM Choice
What is the difference between an SLM and an LLM?
SLMs contain fewer than 15 billion parameters and are purpose-built for specific tasks in low-resource environments — edge devices, private servers, on-device mobile applications. LLMs operate at 100 billion parameters and above, trained on diverse internet-scale corpora to handle broad reasoning across virtually any domain. The difference isn't just scale; it's design philosophy. SLMs optimize for efficiency, speed, and task specificity. LLMs optimize for knowledge breadth and generalization. Both use transformer-based architectures; the divergence is in parameter count, training data diversity, deployment hardware requirements, and the operational overhead each carries.
Is an SLM cheaper to run than an LLM?
Yes, substantially. SLMs require a fraction of the GPU memory, enabling deployment on local workstations, private servers, and consumer devices rather than datacenter-scale GPU clusters. Hosted SLM APIs typically charge $0.10–$0.50 per million tokens, compared to $3–$30 per million for frontier LLM APIs. On self-hosted infrastructure, per-query inference costs for SLMs approach near-zero after the initial hardware investment. Enterprises deploying SLMs for high-volume workloads routinely report 5–20x cost reductions compared to equivalent LLM API consumption. The caveat: that savings calculation must account for MLOps overhead, infrastructure management, and the engineering cost of fine-tuning and maintaining private model deployments.
Can an SLM be as accurate as an LLM?
On narrow, targeted tasks — yes, and sometimes more accurate. A domain-specialized SLM fine-tuned on high-quality annotated data consistently matches or exceeds a generalist LLM on its home task. This has been demonstrated across medical classification, legal entity extraction, code completion, and structured data transformation. The critical qualifier is narrow and well-defined. As task scope widens, SLMs hit the limits of their parametric memory and training distribution. For open-ended, multi-domain, or highly compositional reasoning tasks, frontier LLMs retain a meaningful advantage. The key design principle: fine-tune an SLM on a representative, high-quality dataset for your specific use case and evaluate it directly against the LLM alternative before assuming the larger model is better.
What is model distillation in the context of SLM vs LLM?
Knowledge distillation is the process of using a large "teacher" model (typically a frontier LLM like GPT-4 or Claude Opus) to train a smaller "student" model (an SLM). The teacher generates synthetic training data — reasoning chains, annotated examples, output probability distributions — that the student learns to replicate. The student model absorbs reasoning patterns and task-specific behavior from the teacher, producing a small model that performs well above its raw parameter count would suggest. This technique is how Microsoft built Phi-4: extensive synthetic data generation using larger teacher models, resulting in a 3.8B parameter model with graduate-level reasoning on certain benchmarks. The distillation pipeline involves directing the teacher toward a target domain, generating labeled outputs, and fine-tuning the student through supervised learning or probability-matching objectives.
Can you run an SLM locally or on-premises?
Yes. Many open-weight SLMs under 8B parameters run on modern consumer laptops using tools like Ollama or LM Studio — no internet connection required. A Phi-4 3.8B model runs on any machine with 8 GB of RAM; Llama 3.2 3B runs on iPhone 12 and Android flagship hardware. At the enterprise level, a single NVIDIA A10G or RTX 4090 GPU serves production-scale traffic for a Mistral 7B deployment. With INT4 quantization, even 13B parameter models fit within 8–10 GB of VRAM, making them viable on workstation-class hardware. Air-gapped deployment — with no external network access — is entirely feasible for SLMs, a requirement for military, government, and sensitive healthcare environments where frontier LLM cloud APIs are categorically off the table.
How does RAG help Small Language Models?
RAG (Retrieval-Augmented Generation) directly compensates for the SLM's primary structural weakness: limited parametric memory. Instead of relying on the model's trained weights to "know" the answer, RAG retrieves relevant passages from an external knowledge base — indexed using vector embeddings — and injects them directly into the prompt. The SLM then reasons over that provided context rather than from internal memory. This means a 7B model can accurately answer questions about a proprietary product released after its training cutoff, reason over confidential internal documentation, or stay current with rapidly changing regulations — none of which require the model to have been trained on that specific information. The combination of an SLM for reasoning and a vector database for knowledge retrieval produces systems that are more accurate on enterprise-specific tasks than a generalist LLM operating from memory alone.
What are the security advantages of using an SLM?
The fundamental advantage is data residency. When an SLM runs on your own hardware — whether an on-premises server, a private cloud instance, or an edge device — your prompt data never leaves your network. No third-party API logs your queries. No vendor's data handling policy governs your sensitive inputs. This matters enormously in financial services, healthcare, legal, and government sectors where data sovereignty is a compliance requirement. Beyond residency, self-hosted SLMs provide behavioral stability: the model doesn't receive silent updates that change its output behavior without your knowledge. You can audit model outputs, freeze a specific version for reproducibility, and implement custom alignment fine-tuning to enforce domain-specific behavioral guardrails that a SaaS LLM API cannot offer.
References and Citations
This article is backed by authoritative research, technical documentation, and industry reporting from the following sources:
Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. NIPS Deep Learning Workshop. https://arxiv.org/abs/1503.02531
SitePoint — Quantized Local LLMs: 4-bit vs 8-bit Performance Analysis (2026). https://www.sitepoint.com/quantized-local-llms-4bit-vs-8bit-analysis/
SitePoint — Q4_K_M vs AWQ vs FP16 for Local LLMs (2026). https://www.sitepoint.com/quantization-explained-q4km-vs-awq-vs-fp16-for-local-llms/
Spheron Network — GPU Memory Requirements for LLMs: How to Calculate VRAM (2026). https://www.spheron.network/blog/gpu-memory-requirements-llm/
Microsoft — Phi-4 Technical Report. https://arxiv.org/abs/2412.08905
Intuz — Top 10 Small Language Models in 2026. https://www.intuz.com/blog/best-small-language-models
IntuitionLabs — AI API Pricing Comparison 2026. https://intuitionlabs.ai/articles/ai-api-pricing-comparison-grok-gemini-openai-claude
PE Collective — LLM API Pricing 2026. https://pecollective.com/blog/llm-api-pricing-comparison/
Domino Data Lab / Computer Weekly — Distillation Brings LLM Power to SLMs. https://www.computerweekly.com/blog/CW-Developer-Network/SLM-series-Domino-Data-Lab-Distillation-brings-LLM-power-to-SLMs
InfoWorld — Small Language Models: Rethinking Enterprise AI Architecture (2026). https://www.infoworld.com/article/4160404/small-language-models-rethinking-enterprise-ai-architecture.html
arXiv — A Survey on Collaborative Mechanisms Between Large and Small Language Models (2025). https://arxiv.org/pdf/2505.07460
arXiv — A Survey on Knowledge Distillation of Large Language Models (2024). https://arxiv.org/pdf/2402.13116
Iterathon — Small Language Models 2026: Cut AI Costs 75% with Enterprise SLM Deployment. https://iterathon.tech/blog/small-language-models-enterprise-2026-cost-efficiency-guide
Red Hat — SLMs vs LLMs: What Are Small Language Models? https://www.redhat.com/en/topics/ai/llm-vs-slm
DataCamp — SLMs vs LLMs: A Complete Guide. https://www.datacamp.com/blog/slms-vs-llms
As enterprises navigate the shift from generic applications to specialized intelligence, building the right operational framework is essential. To explore how customized models, advanced RAG architectures, and agentic workflows can drive structural efficiency for your organization, visit FourfoldAI.
Disclaimer
The information provided in this article is intended for general educational and informational purposes only. While every effort has been made to ensure accuracy and factual consistency, AI models, pricing structures, and technical benchmarks evolve rapidly. Readers should conduct independent verification before making enterprise infrastructure or purchasing decisions. For full terms, please review the FourfoldAI Disclaimer.
About the Author
Muizz Shaikh is an AI enthusiast and digital technology professional at FourfoldAI. He is passionate about exploring AI tools, industry trends, and practical applications of emerging technologies. Through FourfoldAI, Muizz contributes to simplifying artificial intelligence for businesses and learners. Connect with him on LinkedIn: linkedin.com/in/muizz-shaikh-45b449403/



Comments