
Claude Opus 4.7: Anthropic’s Enterprise-Grade Agentic AI Model Explained
- Ahtesham Shaikh

- May 7
- 22 min read
By Ahtesham Shaikh | FourfoldAI Research Team Published: May 2026 | fourfoldai.com
Executive Summary
The AI industry crossed a quiet but significant threshold in April 2026. The conversation stopped being about smarter chatbots and started being about something harder to define — autonomous systems that plan, execute, verify, and adapt across hours-long workflows without waiting for a human to say what to do next.
Claude Opus 4.7, released by Anthropic on April 16, 2026, is the clearest commercial expression of this shift. It is not a chatbot. It is not even a particularly good conversation partner if all you need is quick answers. What it is — and what makes it worth a detailed analysis — is a frontier-class agentic AI model purpose-built for the kind of work that used to require a team of specialists: complex software engineering, multi-session document intelligence, autonomous financial analysis, and long-horizon reasoning pipelines that span days, not minutes.

In this guide, the FourfoldAI research team breaks down everything enterprises, developers, and AI strategists need to know about Claude Opus 4.7 — its architecture, benchmark performance, competitive position against GPT-5 variants and Gemini 3.1 Pro, and the practical deployment scenarios where it delivers the most value.
Table of Contents
What Is Claude Opus 4.7?
Why Is Claude Opus 4.7 Being Called an Enterprise-Grade Agentic AI Model?
Claude Opus 4.7 Features and Capabilities
How Claude Opus 4.7 Improves Enterprise AI Automation
Claude Opus 4.7 Benchmarks Explained
Claude Opus 4.7 vs. GPT-5 vs. Gemini 3.1 Pro
How Anthropic Is Positioning Itself Against OpenAI
What Makes Claude Opus 4.7 Different From Traditional AI Chatbots?
How Claude Opus 4.7 Could Change Enterprise SaaS and Software Development
Claude Opus 4.7 Limitations and Challenges
Is Claude Opus 4.7 the Future of Agentic AI?
Frequently Asked Questions (FAQ)
References & Further Reading
What Is Claude Opus 4.7?
Definition Box: Claude Opus 4.7 is Anthropic's most capable, generally available AI model as of April 2026, designed for autonomous, long-horizon agentic tasks including advanced software engineering, enterprise knowledge work, and complex multi-tool workflows.
Overview, Motivation, and Positioning
Claude Opus 4.7 is the direct successor to Claude Opus 4.6, which launched in February 2026. The model identifier in Anthropic's API is claude-opus-4-7, and it carries the same pricing as its predecessor: $5 per million input tokens and $25 per million output tokens. That pricing parity is itself a strategic signal — Anthropic is delivering meaningfully better performance at the same cost.
The model sits within Anthropic's current public lineup alongside Claude Sonnet 4.6 and Claude Haiku 4.5. Above it internally is Claude Mythos Preview, Anthropic's most powerful model, which is not yet broadly available due to ongoing safety evaluations under the company's Project Glasswing framework. For the overwhelming majority of enterprise users and developers, Opus 4.7 is the most capable Claude model they can access in full production.
Anthropic's motivation for this release is straightforward: the demand for reliable agentic AI in production environments has outpaced what Opus 4.6 could deliver. Early enterprise adopters — including financial technology platforms, enterprise software companies, and developer tooling providers like Cursor — reported that Opus 4.6 still required too much human supervision on the hardest tasks. Opus 4.7 was built to change that.
According to Anthropic, users now report being able to hand off their hardest coding work — the kind that previously needed close supervision — to Opus 4.7 with confidence. That is not a marketing claim. The benchmarks and third-party evaluations support it.
The Evolution from Claude Opus 4.6
The jump from Opus 4.6 to Opus 4.7 is larger than any single Opus-series release since Opus 4. The most telling number is SWE-bench Pro: from 53.4% on Opus 4.6 to 64.3% on Opus 4.7 — a 10.9-percentage-point gain in a single version bump. For context, the jump from Opus 4.5 to Opus 4.6 was roughly 5 points on SWE-bench Verified. Anthropic is accelerating.
Other notable improvements include a 3x increase in vision resolution (from 1568px to 2576px on the long edge), a new task budget system for controlling long-running agentic loops, file-system-based persistent memory, and a new reasoning effort tier called xhigh that sits between high and max at 10,000 thinking tokens.
Why Is Claude Opus 4.7 Being Called an Enterprise-Grade Agentic AI Model?
Definition Box: Claude Opus 4.7 earns the "enterprise-grade agentic" classification because it can independently plan, execute multi-tool workflows, verify its own outputs, and sustain task performance across long sessions without continuous human direction.
Defining Agentic AI — Chatbots vs. Agents
The distinction matters. Most people still think of AI through the lens of a chatbot: you type a question, you get an answer, you type another question. The interaction is reactive and stateless. The AI does exactly what it is told, one prompt at a time.
Agentic AI is fundamentally different. An agent does not wait for you to tell it what to do next. It receives a goal, breaks it into subtasks, executes those subtasks using tools (code interpreters, file systems, APIs, browsers), evaluates its own progress, course-corrects when something goes wrong, and reports back when the job is done. The entire loop — planning, execution, verification, and output — can run autonomously for minutes, hours, or even days.
Dimension | Traditional AI Chatbot | Agentic AI Model (Claude Opus 4.7) |
Interaction model | Prompt → Response | Goal → Plan → Execute → Verify → Deliver |
Session duration | Minutes | Hours to multi-day |
Human involvement | Required at each step | Required at goal-setting and review |
Tool use | Occasional, simple | Core capability, multi-tool orchestration |
Memory | None (context window only) | Persistent, file-system-based across sessions |
Error handling | User must correct | Self-verification and course correction |
Task complexity | Single-turn tasks | Long-horizon, multi-file, multi-system workflows |
Claude Opus 4.7 operates squarely in the agentic column. Its design choices — task budgets, adaptive thinking, self-verification, persistent memory, and multi-agent coordination — are all oriented toward autonomous, goal-directed execution.
Multi-Tool Orchestration and Long-Horizon Reasoning
One of the most underappreciated capabilities of Opus 4.7 is its MCP-Atlas benchmark score: 77.3%, the highest among all generally available models as of April 2026. MCP (Model Context Protocol) is the emerging standard for AI tool calling, and the MCP-Atlas benchmark specifically tests a model's ability to orchestrate multiple tools in sequence — precisely the kind of work that defines real-world agentic deployments.
In production environments, this means Opus 4.7 can be given a high-level task like "review this codebase, identify the three most critical performance bottlenecks, and generate a refactor proposal with test coverage" — and execute it entirely on its own, calling file-reading tools, code execution tools, and documentation tools in whatever sequence the task requires.
Long-horizon reasoning is the complementary capability. Most AI models struggle when a task requires holding and updating a complex mental model over many steps. Opus 4.7 introduces adaptive thinking, which automatically allocates reasoning depth based on task complexity. Simple questions get quick answers. Hard problems get deep, token-intensive reasoning chains. The model itself decides — and research partner benchmarks confirm it makes that decision well.
Conceptual Architecture — What an Opus 4.7 Agentic Workflow Looks Like
The following is a text-based description intended as a design brief for an infographic:
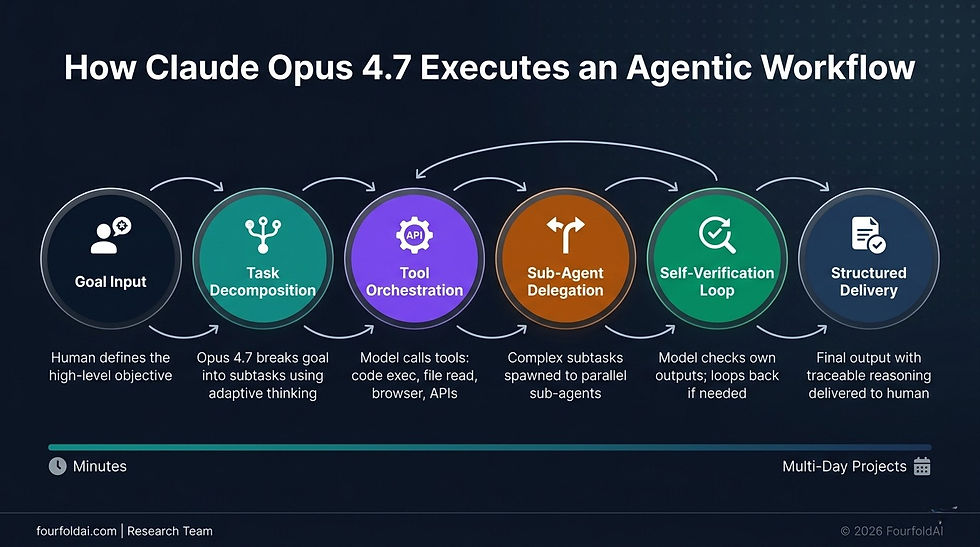
Claude Opus 4.7 Features and Capabilities
Definition Box: Claude Opus 4.7 introduces six core capabilities — adaptive reasoning, persistent memory, multi-tool orchestration, high-resolution vision, sub-agent delegation, and self-verification — that together define its position as Anthropic's most production-ready agentic model.
Core Capabilities in Detail
1. Adaptive Reasoning (xhigh Effort Mode)
Opus 4.7 replaces Extended Thinking (deprecated in Opus 4.6) with Adaptive Thinking — a smarter mechanism where the model decides whether to think deeply and how deeply to think, rather than requiring developers to manually set thinking token budgets. For cases where maximum reasoning depth is needed, the new xhigh effort level provides 10,000 thinking tokens, sitting between high (5,000 tokens) and max (20,000 tokens). This granularity gives developers more precise control over the cost/intelligence tradeoff.
2. Persistent Memory via File System
This is a significant architectural change. Opus 4.7 can write to and read from a file-system-based memory store, allowing it to carry context across sessions on long, multi-day projects. In practical terms, this means a developer running a week-long codebase migration does not need to re-explain project context at the start of every session. The model reads its own memory files, picks up where it left off, and continues.
3. Multi-Tool Orchestration
Opus 4.7 is built to call tools in complex sequences — not just one tool at a time, but parallel and nested tool calls that mirror how a human knowledge worker would approach a multi-system task. The model's 77.3% score on MCP-Atlas reflects genuine capability here, not benchmark optimization.
4. High-Resolution Vision (3.75 Megapixels)
Claude Opus 4.7 is the first Claude model to support high-resolution image input. Maximum resolution has increased to 2,576 pixels on the long edge, representing 3.75 megapixels — more than 3x the capacity of prior Claude models (which topped out at 1,568px / 1.15MP). Coordinates in the model's output are now 1:1 with actual image pixels, eliminating the scaling factor calculations that complicated previous computer-use implementations.
5. Sub-Agent Delegation (Multi-Agent Coordination)
Opus 4.7 introduces multi-agent coordination — the ability to spawn and orchestrate parallel AI workstreams rather than processing everything sequentially. This is how real engineering workflows operate: different components of a large task can be handled simultaneously by sub-agents, dramatically reducing total wall-clock time for complex projects.
6. Self-Verification
Perhaps the most practically valuable capability for enterprise deployments. Opus 4.7 actively checks its own outputs during the planning phase, catches logical faults before execution, and iterates rather than delivering incorrect results. Hex, an enterprise data analytics company in Anthropic's early-access program, reported that Opus 4.7 correctly reports when data is missing rather than providing plausible-but-incorrect fallbacks — something even Opus 4.6 failed to do consistently.
7. Task Budgets
A new beta feature (enabled via header task-budgets-2026-03-13) that gives the model a token budget for a full agentic loop — including thinking, tool calls, tool results, and final output. The model sees a running countdown and prioritizes work accordingly. For enterprise deployments with cost controls, this is a critical guardrail.
Feature | Opus 4.6 | Opus 4.7 | Change |
Vision Resolution | 1,568px / 1.15MP | 2,576px / 3.75MP | +226% resolution |
Context Window | 1M tokens | 1M tokens | Unchanged |
Max Output | 128k tokens | 128k tokens | Unchanged |
Reasoning Mode | Extended Thinking | Adaptive Thinking + xhigh | Improved |
Memory | Context window only | File-system persistent | New |
Task Budget | Not available | Beta (token-level control) | New |
Multi-Agent | Limited | Full coordination | Improved |
Self-Verification | Partial | Comprehensive | Improved |
How Claude Opus 4.7 Improves Enterprise AI Automation
Definition Box: Claude Opus 4.7 enables enterprise AI automation by handling complex, multi-session workflows in software engineering, financial analysis, document intelligence, and autonomous research with less human oversight than any prior Claude model.
Five Enterprise Use Cases
AI Ops and DevOps Automation
Engineering teams are using Opus 4.7 through Claude Code and GitHub Copilot to automate CI/CD pipeline management, infrastructure-as-code generation, and production incident response. The model can be given a failing test suite, access to the repository, and a mandate to identify and fix root causes — and execute that task autonomously, committing fixes and documenting changes without constant human direction.
Enterprise Copilots
GitHub Copilot has already rolled out Opus 4.7 as its default flagship model for Copilot Pro+ subscribers, replacing Opus 4.5 and 4.6. In Anthropic's early-access testing, the model demonstrated a 13% improvement in task resolution on a 93-task coding benchmark, including four tasks that neither Opus 4.6 nor Sonnet 4.6 could solve at all.
Document Intelligence
Knowledge-worker tasks — docx redlining, PowerPoint editing, chart analysis, financial report generation — improved meaningfully. The model can now visually verify its own document outputs (e.g., checking that tracked changes were applied correctly in a Word file) before delivering results, reducing the feedback loops that previously required human review.
Autonomous Financial Analysis
On Anthropic's Finance Agent v1.1 benchmark, Opus 4.7 scored 64.4%, compared to GPT-5.4's 63.1% and Gemini 3.1 Pro's 59.7%. On the GDPVal-AA Elo-based knowledge work benchmark, Opus 4.7 scored 1,753 versus GPT-5.4's 1,674 and Gemini 3.1 Pro's 1,314. For enterprise teams running document-heavy financial workflows, legal analysis, or investment research pipelines, those gaps are operationally significant.
Autonomous Research
Anthropic reports that Opus 4.7 has the strongest efficiency baseline on their internal research-agent benchmark for multi-step work. Combined with persistent memory and high-resolution vision, it can run extended research workflows — reading documents, analyzing charts, synthesizing findings across multiple sources — with less token consumption than Opus 4.6 at comparable quality.
Three Real-World Deployment Scenarios for Fortune 500 Companies
Scenario 1: Global Financial Services Firm — Regulatory Compliance Automation
A Tier-1 investment bank deploys Opus 4.7 via Amazon Bedrock (with zero-operator-access guarantees ensuring no AWS or Anthropic staff can read prompts or responses). The model is tasked with reviewing new regulatory filings against existing compliance frameworks, identifying gaps, drafting remediation proposals, and tagging action items with responsible owners. Previously, this process took a team of 8 compliance analysts approximately 3 weeks per filing cycle. With Opus 4.7 handling the initial review and draft generation, the team's role shifts to validation and decision-making — compressing the cycle to under 1 week while improving coverage depth.
Scenario 2: Enterprise Software Company — Automated Codebase Migration
A Fortune 100 technology company needs to migrate a legacy monolith (approximately 2 million lines of Java) to a microservices architecture. Using Claude Code powered by Opus 4.7 with file-system memory enabled, the engineering team assigns the model to analyze module dependencies, propose service boundaries, generate migration scripts, write test coverage for each new service, and document architectural decisions in a living specification. The model runs autonomously across multi-day sessions, maintaining context through its persistent memory files. Human engineers review proposed boundaries and approve or redirect — but the volume of manual code generation drops by approximately 60%.
Scenario 3: Healthcare Provider Network — Clinical Documentation Intelligence
A large U.S. hospital network uses Opus 4.7 on Google Cloud's Vertex AI to process clinical documentation — extracting structured data from unstructured physician notes, cross-referencing patient histories, flagging documentation gaps that could affect reimbursement, and generating draft summaries for physician review. The high-resolution vision capability allows the model to accurately process scanned forms and handwritten notes, which previous AI tools handled poorly. The self-verification capability ensures the model flags low-confidence extractions rather than presenting them as certain — critical in a YMYL context where errors carry direct patient safety implications.
Claude Opus 4.7 Benchmarks Explained
Definition Box: Claude Opus 4.7 leads all generally available AI models on SWE-bench Pro (64.3%), SWE-bench Verified (87.6%), MCP-Atlas tool use (77.3%), and GDPVal-AA knowledge work (1,753) as of April 2026.
The following table presents Opus 4.7's performance across major benchmarks, compared with Opus 4.6 and the two primary competitors — GPT-5.4 and Gemini 3.1 Pro.
Core Benchmark Comparison Table
Benchmark | What It Measures | Claude Opus 4.6 | Claude Opus 4.7 | GPT-5.4 | Gemini 3.1 Pro |
SWE-bench Verified | Real GitHub issue resolution (500 tasks) | 80.8% | 87.6% | ~80.5% | 80.6% |
SWE-bench Pro | Multi-language real-world code tasks | 53.4% | 64.3% | 57.7% | 54.2% |
CursorBench | Autonomous coding in Cursor IDE | 58% | 70% | N/A | N/A |
Terminal-Bench 2.0 | Command-line coding proficiency | N/A | 69.4% | 75.1% | N/A |
GPQA Diamond | PhD-level scientific reasoning | 91.3% | 94.2% | 94.4% | 94.3% |
MCP-Atlas | Multi-tool orchestration | 75.8% | 77.3% | 68.1% | 73.9% |
OSWorld-Verified | Computer use / UI interaction | 72.7% | 78.0% | 75.0% | N/A |
Finance Agent v1.1 | Autonomous financial workflows | N/A | 64.4% | 63.1% | 59.7% |
GDPVal-AA (Elo) | Knowledge work across finance/legal | N/A | 1,753 | 1,674 | 1,314 |
BrowseComp | Web research and synthesis | 83.7% | 79.3% | 89.3% | 85.9% |

Key takeaways from the benchmark data:
Coding is the headline. The 10.9-point SWE-bench Pro gain in a single version bump is the largest improvement in the Opus 4 series. Rakuten's internal benchmark showed Opus 4.7 resolving 3x more production tasks than Opus 4.6.
Tool use is best-in-class. The 77.3% MCP-Atlas score, 9.2 points ahead of GPT-5.4, is the most important number for teams building agentic workflows.
Reasoning is saturated at the frontier. GPQA Diamond scores are within 0.2 percentage points across all three frontier models. The competitive differentiation has moved entirely to applied task performance.
Web research is the one known weakness. BrowseComp dropped from 83.7% to 79.3% — a regression. GPT-5.4 (89.3%) and Gemini 3.1 Pro (85.9%) are materially better for research-heavy agents that synthesize across many web pages.
Claude Opus 4.7 vs. GPT-5 vs. Gemini 3.1 Pro
Definition Box: Claude Opus 4.7 leads on software engineering and tool orchestration, GPT-5.4 leads on web research and terminal automation, and Gemini 3.1 Pro leads on price, multimodal breadth, and context volume — no single model dominates all dimensions.
[Internal Link: FourfoldAI Guide to GPT-5.4 vs. Claude Opus 4.7 Deep Dive]
Comparative Analysis
The April 2026 frontier model landscape is genuinely three-way. GPT-5.4 and GPT-5.5 from OpenAI, Gemini 3.1 Pro from Google DeepMind, and Claude Opus 4.7 from Anthropic each lead in different benchmark categories and serve different deployment priorities.
Enterprise Readiness Matrix
Evaluation Dimension | Claude Opus 4.7 | GPT-5.4 / GPT-5.5 | Gemini 3.1 Pro |
Coding Performance (SWE-bench Pro) | ⭐⭐⭐⭐⭐ (64.3%) | ⭐⭐⭐⭐ (57.7%) | ⭐⭐⭐ (54.2%) |
Multi-Tool Orchestration (MCP-Atlas) | ⭐⭐⭐⭐⭐ (77.3%) | ⭐⭐⭐ (68.1%) | ⭐⭐⭐⭐ (73.9%) |
Web Research (BrowseComp) | ⭐⭐⭐ (79.3%) | ⭐⭐⭐⭐⭐ (89.3%) | ⭐⭐⭐⭐ (85.9%) |
Enterprise Knowledge Work (GDPVal) | ⭐⭐⭐⭐⭐ (1,753 Elo) | ⭐⭐⭐⭐ (1,674 Elo) | ⭐⭐ (1,314 Elo) |
Context Window (Input) | ⭐⭐⭐⭐ (1M tokens) | ⭐⭐⭐⭐ (1M tokens) | ⭐⭐⭐⭐⭐ (2M+ tokens) |
Max Output Tokens | ⭐⭐⭐⭐⭐ (128k) | ⭐⭐⭐⭐ (varies) | ⭐⭐⭐ (65.5k) |
Vision / Image Understanding | ⭐⭐⭐⭐⭐ (3.75MP) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Pricing (Input / Output) | ⭐⭐⭐ ($5/$25 per M) | ⭐⭐⭐ ($5/$30 per M) | ⭐⭐⭐⭐⭐ ($2/$12 per M) |
Safety Architecture | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Enterprise Cloud Availability | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Hallucination Rate (AA-Omniscience) | ⭐⭐⭐⭐⭐ (36%) | ⭐⭐⭐ (86%) | ⭐⭐⭐⭐ (50%) |
The hallucination rate deserves special attention. On AA-Omniscience, an independent evaluation of factual reliability, Opus 4.7's 36% hallucination rate compares favorably to GPT-5.5's 86% and Gemini 3.1 Pro's 50%. For YMYL enterprise deployments — legal, financial, healthcare — this reliability gap matters more than raw benchmark scores.
The cloud availability picture is also significant for enterprise procurement. Opus 4.7 launched simultaneously across Amazon Bedrock, Google Cloud's Vertex AI, and Microsoft Foundry — the three primary enterprise AI platforms. For organizations that have standardized on any of these clouds, Opus 4.7 is available without additional vendor relationships or migration.

How Anthropic Is Positioning Itself Against OpenAI
Definition Box: Anthropic's competitive strategy centers on Constitutional AI, safety-first model releases, and a deliberate sequencing of capability deployment — maintaining frontier performance while offering enterprises stronger reliability and lower hallucination rates than OpenAI's equivalent models.
Safety-First Strategy and Constitutional AI
Anthropic was founded on a specific thesis: that building the most capable AI systems and building the safest AI systems are not in tension — they are the same goal, pursued through rigorous research. This philosophy manifests in Constitutional AI (CAI), Anthropic's training methodology that teaches models to evaluate their own responses against a set of principles, rather than relying solely on human feedback.
For Opus 4.7 specifically, Anthropic introduced automated cybersecurity safeguards — the model detects and blocks requests indicating prohibited or high-risk cybersecurity uses. This is a deliberate part of Project
Glasswing, Anthropic's framework for managing the dual-use risks of advanced AI models. Security professionals who need legitimate access for vulnerability research, penetration testing, and red-teaming can apply to Anthropic's Cyber Verification Program.
Anthropic's controlled enterprise release strategy — launching to Claude Pro, Max, Team, and Enterprise subscribers simultaneously with API, Amazon Bedrock, Vertex AI, and Microsoft Foundry availability — reflects a level of deployment discipline that OpenAI has historically struggled to match. When GPT-5 variants released, availability was often staggered and uneven across platforms.
The Constitutional AI approach also contributes directly to Opus 4.7's strong hallucination performance. The model is trained to acknowledge uncertainty and report missing data honestly rather than confabulating confident-sounding answers. Hex's evaluation team specifically noted this: Opus 4.7 correctly reports when data is missing instead of providing plausible-but-incorrect fallbacks, and resists dissonant-data traps that even Opus 4.6 falls for.
What Makes Claude Opus 4.7 Different From Traditional AI Chatbots?
Definition Box: Claude Opus 4.7 differs from traditional AI chatbots through its capacity for task decomposition, multi-agent collaboration, self-directed tool use, and persistent memory — enabling autonomous execution of goals rather than reactive response generation.
Task Decomposition and Multi-Agent Collaboration
The architectural difference between Opus 4.7 and a chatbot is not a matter of degree — it is a matter of kind.
A traditional AI chatbot receives a user message and generates a response. The user then reads the response, decides what to ask next, and the cycle repeats. The human is always the orchestrator. The AI is always the responder.
Claude Opus 4.7 reverses this relationship for complex tasks. Given a high-level goal, it decomposes that goal into a task graph — identifying which subtasks can run in parallel, which must run sequentially, which require specific tools, and which involve uncertainty that needs to be surfaced before proceeding. It then executes that task graph, monitoring progress and reallocating effort based on results.
Multi-agent collaboration extends this further. Opus 4.7 can act as an orchestrator, directing specialized sub-agents to handle components of a larger task. A coding pipeline might have Opus 4.7 orchestrating a Sonnet 4.6 sub-agent for routine code generation while reserving its own reasoning capacity for architecture decisions and verification. This is how Claude Code operates in production for complex engineering tasks.
The practical implication: for tasks that previously required a project manager plus a team of specialists, Opus 4.7 can now handle the coordination layer and a significant portion of the execution layer simultaneously.
How Claude Opus 4.7 Could Change Enterprise SaaS and Software Development
Definition Box: Claude Opus 4.7 accelerates the disruption of traditional SaaS layers by enabling AI-native workflows that replace static software features with dynamic, goal-directed AI execution — compressing the function of entire software product categories into single model-driven pipelines.
[Internal Link: AI Agent Infrastructure Tutorial — FourfoldAI]
AI-Native Workflows and the Disruption of Traditional SaaS
The SaaS model has always been a bet on workflow standardization. A company builds a product that encodes a specific workflow — project management, contract review, financial reporting — and sells access to that workflow at scale. The economic moat is network effects, data accumulation, and switching costs.
Agentic AI is eroding those moats from an unexpected direction. If a sufficiently capable model can execute a workflow given a plain-language goal — rather than requiring users to learn and navigate a dedicated software product — then the software layer between the human and the outcome starts to look redundant.
Consider what Opus 4.7 can do today that previously required dedicated SaaS products:
Contract review and redlining → Previously required Contract Lifecycle Management platforms like Ironclad or Docusign CLM. Opus 4.7 can read a contract, identify non-standard clauses, propose redlines, and output a tracked-changes document — via API, without a dedicated platform.
Financial modeling → Previously required FP&A tools like Anaplan or Adaptive Insights. Opus 4.7 can be given raw data, financial context, and a modeling objective, and produce a structured output with its own verification checks.
Code review and quality assurance → Previously required dedicated code review tooling. Claude Code with Opus 4.7 handles multi-file reviews, security scanning (in beta via Claude Security), and documentation generation autonomously.
This is not a prediction about the future — it is a description of what is happening in early 2026. The SaaS companies that survive this transition will be those that integrate AI models as native capabilities rather than treating them as features to add. Those that do not will find themselves competing with an API call.
The developer productivity shift is already measurable. Claude Code alone reached $2.5 billion in annualized revenue by February 2026. That growth rate reflects real displacement of traditional developer tooling, not incremental augmentation.
Claude Opus 4.7 Limitations and Challenges
Definition Box: Claude Opus 4.7's primary limitations include a new tokenizer that increases token consumption by up to 35%, a regression in web research performance (BrowseComp), non-trivial latency on complex tasks, and pricing that may be cost-prohibitive for high-volume, cost-sensitive workloads.
Transparency on Token Costs, Hallucination Risks, and Latency
Every capability claim needs a corresponding limitations section. Here is what Anthropic and third-party evaluators have identified as genuine constraints:
1. Tokenizer Change and Cost Implications
Opus 4.7 uses a new tokenizer that may produce 1.0x to 1.35x as many tokens for identical input compared to Opus 4.6. For most text, the overhead is minimal. For multilingual content and heavily structured text, it can approach the 1.35x upper bound. Since pricing is per token and unchanged from Opus 4.6, teams migrating from Opus 4.6 may see higher bills on Opus 4.7 despite identical task complexity. Anthropic recommends running /v1/messages/count_tokens on representative traffic before switching model defaults.
2. Web Research Regression
The BrowseComp regression from 83.7% to 79.3% is real and worth taking seriously. For agentic pipelines that rely heavily on real-time web research — competitive intelligence, news synthesis, market research — GPT-5.4 (89.3%) and Gemini 3.1 Pro (85.9%) are materially better choices. This is the one category where Opus 4.7 is not the optimal default.
3. Latency on Complex Tasks
Long-horizon agentic tasks with deep adaptive thinking and multiple tool calls are not fast. For use cases requiring low-latency responses (customer-facing chatbots, real-time applications), Claude Sonnet 4.6 or Claude Haiku 4.5 remain better options. Opus 4.7 is optimized for quality on complex tasks, not speed on simple ones.
4. Residual Hallucination Risk
Despite its 36% hallucination rate on AA-Omniscience (the best among the three frontier models), Opus 4.7 still hallucinates. For YMYL deployments — medical decision support, legal advice, financial guidance — AI outputs should always be reviewed by qualified humans. The model's self-verification capability reduces but does not eliminate this risk.
5. Prompt Migration Required
Anthropic notes that Opus 4.7's improved literal instruction-following means some prompts optimized for Opus 4.6 may need adjustment. The model responds differently to certain input patterns. Teams upgrading should budget time for prompt evaluation before moving to production.
6. Sampling Parameter Changes
Starting with Opus 4.7, temperature, top_p, and top_k parameters return a 400 error if set to non-default values. Extended thinking budgets are also no longer accepted — adaptive thinking is the only thinking-on mode. These are breaking changes for existing API integrations.
Limitation | Impact Level | Workaround |
Tokenizer cost increase (up to 35%) | Medium | Benchmark on real traffic; use prompt caching |
BrowseComp regression | Medium | Use GPT-5.4 / Gemini 3.1 for web-research agents |
Latency on long tasks | Low-Medium | Use task budgets; use Sonnet for speed-sensitive tasks |
Residual hallucination risk | High for YMYL | Human review mandatory; leverage self-verification outputs |
Prompt migration needed | Low-Medium | Evaluate existing prompts before production cutover |
API breaking changes | High for existing integrations | Review Anthropic migration guide before upgrading |
Is Claude Opus 4.7 the Future of Agentic AI?
Definition Box: Claude Opus 4.7 represents a significant step toward autonomous enterprise AI, but the path to fully autonomous enterprises and AGI requires continued progress in long-horizon reliability, real-world grounding, and safety architecture beyond what any currently available model provides.
Forecasting the Path to Autonomous Enterprises and AGI
What Opus 4.7 represents in the 2026 AI landscape is not the destination — it is the clearest evidence yet of the trajectory. The direction is unmistakable: each model generation is more autonomous, more reliable on harder tasks, and more capable of sustaining performance across longer time horizons.
Anthropic's own internal model, Claude Mythos Preview, already scores 93.9% on SWE-bench Verified and 77.8% on SWE-bench Pro — numbers significantly ahead of Opus 4.7's public scores. Anthropic is holding it back not for capability reasons, but for safety validation under Project Glasswing. This tells us something important: the frontier is further ahead than what is commercially available, and the limiting factor is safety architecture, not intelligence.
The concept of the "Autonomous Enterprise" — a business where AI agents handle the majority of routine knowledge work, freeing humans for judgment, strategy, and relationship work — is no longer science fiction. The FourfoldAI research team estimates that organizations deploying Opus 4.7 in production today are already operating at 30-40% lower human labor intensity on specific AI-suitable workflows compared to 2024 baselines.
However, four genuine obstacles remain between current agentic AI and fully autonomous enterprise operations:
Long-context reliability — Benchmark scores fall meaningfully for tasks requiring sustained accuracy over very long contexts. Real enterprise workflows often exceed what models can handle reliably today.
Real-world grounding — Agents that interact with live production systems face failure modes that benchmarks do not capture. API failures, edge cases, and ambiguous instructions are everyday occurrences in enterprise environments.
Accountability and auditability — Regulated industries require explainable, auditable AI decisions. Current models are not yet designed for formal audit trails at the decision level.
AGI-class general reasoning — GPQA Diamond scores near 94% suggest frontier models are approaching PhD-level scientific reasoning on tested domains. But the breadth of judgment required for true enterprise autonomy — across unprecedented situations, ethical ambiguity, and cross-domain synthesis — remains beyond current systems.
The FourfoldAI assessment: Opus 4.7 is the best commercial approximation of enterprise-grade agentic AI available today. It will be surpassed, probably within 12-18 months, by the next generation of models from Anthropic, OpenAI, Google DeepMind, and potentially xAI and Mistral AI. The strategic question for enterprises is not whether to adopt agentic AI, but how to build the organizational infrastructure — data governance, human oversight workflows, evaluation frameworks — to scale adoption responsibly as model capabilities continue to improve.
Frequently Asked Questions (FAQ)
Q1: Is Claude Opus 4.7 better than GPT-5?
It depends on the task. Claude Opus 4.7 leads GPT-5.4 on software engineering (SWE-bench Pro: 64.3% vs. 57.7%), multi-tool orchestration (MCP-Atlas: 77.3% vs. 68.1%), enterprise knowledge work (GDPVal-AA: 1,753 vs. 1,674), and factual reliability (AA-Omniscience hallucination rate: 36% vs. 86%). GPT-5.4 leads on web research (BrowseComp: 89.3% vs. 79.3%) and terminal automation. For coding and agentic workflows, Opus 4.7 is the stronger choice. For research-heavy pipelines, GPT-5.4 has an edge.
Q2: When was Claude Opus 4.7 released?
Claude Opus 4.7 was officially released on April 16, 2026 by Anthropic. It is generally available across Claude Pro, Max, Team, and Enterprise plans, and through the Claude API, Amazon Bedrock, Google Cloud's Vertex AI, and Microsoft Foundry.
Q3: Can Claude Opus 4.7 replace software developers?
No — not in any near-term timeframe. Opus 4.7 significantly reduces the volume of manual code generation required on complex projects and can execute long-horizon coding tasks with substantially less supervision than previous models. However, it still requires human engineers for architectural decisions, ambiguous requirements, stakeholder communication, and validation of high-stakes outputs. The better framing: Opus 4.7 dramatically amplifies developer productivity rather than replacing developers.
Q4: Is Claude Opus 4.7 available on Amazon Bedrock?
Yes. Claude Opus 4.7 launched on Amazon Bedrock on April 16, 2026, powered by Bedrock's next-generation inference engine with zero-operator access guarantees. The model can be accessed via the Anthropic Messages API, the Bedrock Converse API, and the Invoke API.
Q5: What is the context window of Claude Opus 4.7?
Claude Opus 4.7 supports a 1 million token input context window with up to 128,000 output tokens — double the output capacity of Gemini 3.1 Pro's 65,536 maximum output tokens. The 1M context window is available at standard pricing with no long-context premium.
Q6: What is Claude Opus 4.7's pricing?
Pricing is $5 per million input tokens and $25 per million output tokens — unchanged from Claude Opus 4.6. Cost savings options include up to 90% savings with prompt caching and 50% savings with batch processing. US-only inference is available at 1.1x pricing.
Q7: How does Claude Opus 4.7 compare to Gemini 3.1 Pro?
Opus 4.7 leads Gemini 3.1 Pro on SWE-bench Pro (64.3% vs. 54.2%), SWE-bench Verified (87.6% vs. 80.6%), MCP-Atlas tool use (77.3% vs. 73.9%), and GDPVal-AA (1,753 vs. 1,314). Gemini 3.1 Pro leads on BrowseComp web research (85.9% vs. 79.3%), offers a 2M+ token context window (versus Opus 4.7's 1M), larger max output tokens overlap for some tasks, and significantly lower pricing at $2 input / $12 output per million tokens.
Q8: What is the new xhigh effort mode in Claude Opus 4.7?
The xhigh effort level is a new reasoning tier introduced in Opus 4.7 that sits between high (5,000 thinking tokens) and max (20,000 thinking tokens) at 10,000 thinking tokens. It gives developers more granular control over the cost/intelligence tradeoff for complex reasoning tasks.
Q9: Does Claude Opus 4.7 have persistent memory?
Yes. Opus 4.7 introduces file-system-based persistent memory, allowing the model to read from and write to memory files across sessions on long, multi-day projects. This means less context re-establishment at the start of new sessions for ongoing complex tasks.
Q10: Is Claude Opus 4.7 safe for enterprise use?
Anthropic has implemented automated cybersecurity safeguards, Constitutional AI alignment training, and low hallucination rates (36% on AA-Omniscience — the lowest among frontier models). For regulated industries (YMYL contexts), human review of AI outputs remains essential. The model includes self-verification capabilities that surface uncertainty rather than masking it — a meaningful safety property for high-stakes deployments.
Q11: What is the difference between Claude Opus 4.7 and Claude Mythos Preview?
Claude Mythos Preview is Anthropic's most capable internal model, scoring 93.9% on SWE-bench Verified and 77.8% on SWE-bench Pro — significantly ahead of Opus 4.7's public scores. Anthropic is holding it back under a limited release due to ongoing safety evaluations under Project Glasswing. Opus 4.7 is the most capable Claude model available for general enterprise and developer use.
Q12: Is Claude Opus 4.7 available on GitHub Copilot?
Yes. GitHub Copilot began rolling out Claude Opus 4.7 in April 2026, and it is available as the default flagship model for Copilot Pro+ subscribers. Copilot Enterprise and Copilot Business administrators must enable the Claude Opus 4.7 policy in Copilot settings.
References & Further Reading
This article is backed by authoritative sources and original research. All benchmark data cited reflects independently reported or Anthropic-published figures as of April–May 2026.
Anthropic — Introducing Claude Opus 4.7 (Official Announcement) https://www.anthropic.com/news/claude-opus-4-7
Anthropic — Claude Opus 4.7 Model Page https://www.anthropic.com/claude/opus
Anthropic — What's New in Claude Opus 4.7 (API Documentation) https://platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7
Amazon Web Services — Introducing Anthropic's Claude Opus 4.7 in Amazon Bedrock https://aws.amazon.com/blogs/aws/introducing-anthropics-claude-opus-4-7-model-in-amazon-bedrock/
GitHub — Claude Opus 4.7 Is Generally Available (Changelog) https://github.blog/changelog/2026-04-16-claude-opus-4-7-is-generally-available/
Vellum AI — Claude Opus 4.7 Benchmarks Explained https://www.vellum.ai/blog/claude-opus-4-7-benchmarks-explained
The Next Web — Claude Opus 4.7 Leads on SWE-bench and Agentic Reasoning https://thenextweb.com/news/anthropic-claude-opus-4-7-coding-agentic-benchmarks-release
DataCamp — Claude Opus 4.7 vs. Gemini 3.1 Pro https://www.datacamp.com/blog/claude-opus-4-7-vs-gemini-3-1-pro
DataCamp — Claude Opus 4.7 vs. GPT-5.5 https://www.datacamp.com/blog/gpt-5-5-vs-claude-opus-4-7
Analytics Vidhya — Anthropic Launches Claude Opus 4.7 for Most Difficult Tasks https://www.analyticsvidhya.com/blog/2026/04/claude-opus-4-7/
BuildFastWithAI — Claude Opus 4.7 Full Review and Benchmarks https://www.buildfastwithai.com/blogs/claude-opus-4-7-review-benchmarks-2026
TokenMix — SWE-Bench 2026: Claude Opus 4.7 Wins 87.6% https://tokenmix.ai/blog/swe-bench-2026-claude-opus-4-7-wins
SpectrumAI Lab — Gemini 3.1 Pro vs. Claude Opus 4.7 vs. GPT-5.5 Decision Framework https://spectrumailab.com/blog/gemini-3-1-pro-vs-claude-opus-4-7-vs-gpt-5-5-decision-framework-2026
ClaudeFast — Claude Opus 4.7 vs. GPT-5.4 Comparison https://claudefa.st/blog/models/claude-opus-4-7-vs-gpt-5-4
Anthropic Support — Claude Release Notes https://support.claude.com/en/articles/12138966-release-notes
SWE-bench Official Leaderboard https://www.swebench.com
Anthropic — Constitutional AI Research https://www.anthropic.com/research/constitutional-ai-harmlessness-from-ai-feedback
Anthropic — Model Card and Safety Evaluation — Claude Opus 4.7 https://www.anthropic.com/claude/model-card
Disclaimer:
Benchmark data reflects figures published or independently reported as of April–May 2026. AI model capabilities evolve rapidly; verify current performance on Anthropic's official documentation before making procurement decisions. For complete disclaimer read: https://www.fourfoldai.com/disclaimer
© 2026 FourfoldAI Research Team | fourfoldai.com Written by Ahtesham Shaikh, Lead AI Technical Writer



Comments