
Synthetic Data in AI: Benefits, Use Cases & Future of AI Training (2026)
- Shaikhmuizz javed
- May 6
- 11 min read

By Shaikh Muizz | FourfoldAI Research Team | Published: May 2026
📌 What is Synthetic Data in AI? Synthetic data in AI refers to artificially generated datasets — created by algorithms, simulations, or generative models — that statistically mimic real-world data without containing actual personal or sensitive information. In 2026, it has become a critical pillar of modern AI training, addressing data scarcity, privacy regulations, and the prohibitive cost of real-world data collection.
We are in the middle of a data crisis — and most people don't realize it yet. Every major AI model being built today, from large language models to autonomous robotics systems, runs on one thing: data. Enormous, diverse, high-quality synthetic data in AI pipelines are now what separate the teams winning the AI race from those falling behind. Real-world data is running out, privacy laws are tightening, and the cost of manual data labeling is skyrocketing. Synthetic data isn't just a workaround anymore. It is, quite simply, the future of AI training.

What is Synthetic Data in AI and Why is it Important?
💡 Quick Answer: Synthetic data in AI is machine-generated data that mirrors the statistical properties of real datasets. It is important because it solves the data scarcity problem, enables GDPR/CCPA-compliant AI development, and dramatically reduces the cost and time of building training datasets.
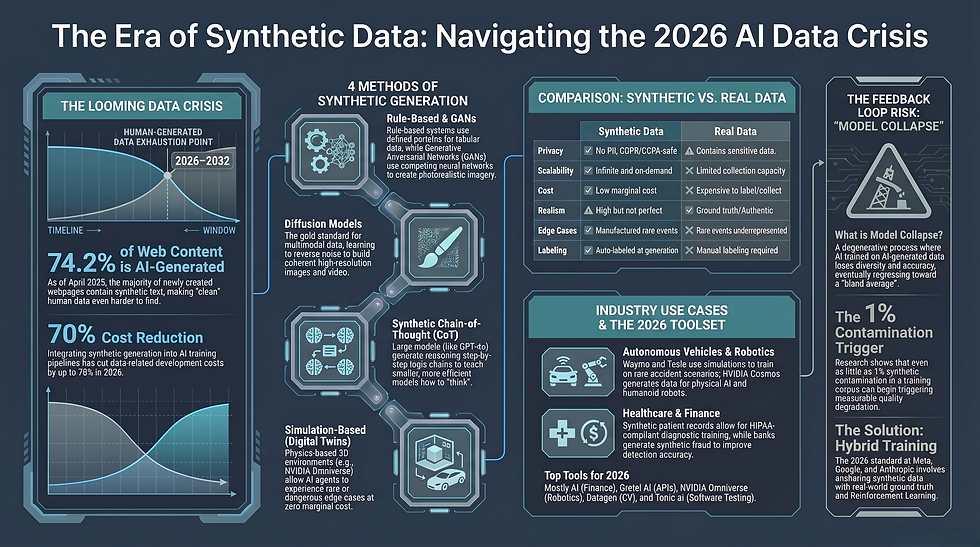
The data scarcity problem is real and growing. As of 2026, researchers at Epoch AI have warned that the internet may run out of usable, high-quality human-generated text for training purposes somewhere between 2026 and 2032. Think about that. The very foundation that models like GPT-4, Gemini, and Claude were built on is approaching exhaustion.
At the same time, regulations like GDPR in Europe and CCPA in California have made it legally risky — and in some cases outright impossible — to use real patient records, financial data, or behavioral data to train AI models. The solution? Generate synthetic equivalents that preserve the statistical truth of real data while containing zero personally identifiable information.
Gartner has projected that synthetic data will surpass real data as the dominant source for AI model training by 2030 — and the momentum is already clearly visible in 2026.
How Does Synthetic Data in AI Work?
💡 Quick Answer: Synthetic data is generated through several methods — rule-based systems, GANs, Diffusion Models, LLM-generated reasoning datasets, and physics-based simulations. Each method serves different data types and use cases.
There isn't one single way to create synthetic data. Here are the five primary generation methods used by AI teams today:
1. Rule-Based Generation The oldest approach. Data scientists define explicit statistical rules and distributions to generate structured tabular data. Think: generating synthetic bank transactions based on known spending patterns. Simple, fast, but limited in capturing complex real-world nuance.
2. GAN-Based Generation (Generative Adversarial Networks) A Generator network creates fake data while a Discriminator tries to spot the fake. They compete until the generator produces data realistic enough to fool the discriminator. GANs are widely used for synthetic image generation, creating photorealistic faces, medical scans, and urban scenes that never existed.
3. Diffusion Models The technology behind tools like DALL-E 3 and Stable Diffusion. Diffusion models work by learning to reverse a noise-addition process — gradually building coherent, high-resolution synthetic images or video frames from random noise. In 2025–2026, diffusion models have become the gold standard for generating synthetic multimodal training data, particularly in autonomous vehicle pipelines.
4. LLM-Generated Data (Synthetic Chain-of-Thought) This is where things get genuinely fascinating — and where most competitors miss the story entirely. Large Language Models like GPT-4o and Claude 3.5 are now used to generate entire reasoning datasets. Researchers prompt these models to produce step-by-step logic chains — called Synthetic Chain-of-Thought (CoT) data — to train smaller, more efficient models to reason better. OpenAI's o1 and o3 models were partially trained on this kind of synthetic reasoning data. It's an AI teaching an AI how to think.
5. Simulation-Based Generation Used heavily in robotics and autonomous vehicles. Tools like NVIDIA Omniverse build photorealistic 3D virtual worlds where AI agents can experience thousands of driving scenarios, factory accidents, or surgical procedures — events that are rare, dangerous, or impossible to collect in the real world — at virtually zero marginal cost.
Why Are AI Companies Using Synthetic Data in AI?
💡 Quick Answer: AI companies turn to synthetic data because it addresses five critical problems simultaneously: data shortages, privacy compliance, development speed, cost reduction, and the generation of rare edge-case scenarios for AI agents.
Let's be direct about why every serious AI lab is investing in synthetic AI datasets:
Data Shortage — Quality labeled real-world data is finite and increasingly expensive. Synthetic data can scale infinitely on demand.
Privacy & Compliance — Synthetic patient records, financial transactions, and user behavior logs contain zero PII, making them GDPR and CCPA-safe by design.
Speed — What takes months to collect and label in the real world can be generated in hours with a well-tuned synthetic data pipeline.
Cost Reduction — Reports from 2026 indicate organizations are cutting data-related development costs by up to 70% by integrating synthetic generation into their AI training pipelines.
Edge-Case Scenario Generation — Perhaps the most underrated benefit. Real datasets are inherently biased toward common events. A fraud detection model trained only on real data may never see enough examples of a rare new fraud pattern. Synthetic data lets teams manufacture as many rare-event examples as needed, making AI Agents dramatically more robust.
Synthetic Data in AI vs Real Data — What's the Difference?
💡 Quick Answer: Real data offers unmatched authenticity but comes with privacy risks, collection costs, and labeling burdens. Synthetic data trades some realism for massive gains in scalability, privacy, and compliance. The best AI systems in 2026 use both — a strategy called Hybrid AI Training.
Factor | Synthetic Data | Real Data |
Privacy | ✅ No PII, GDPR/CCPA-safe | ⚠️ Contains sensitive personal data |
Scalability | ✅ Infinite, on-demand generation | ❌ Limited by collection capacity |
Cost | ✅ Low marginal cost at scale | ❌ Expensive to collect and label |
Bias Control | ✅ Can be engineered to reduce bias | ⚠️ Reflects real-world biases |
Realism | ⚠️ High but not perfect | ✅ Ground truth of the real world |
Compliance | ✅ Inherently compliant | ⚠️ Requires anonymization/consent |
Edge Cases | ✅ Can generate rare scenarios | ❌ Rare events are underrepresented |
Labeling | ✅ Auto-labeled at generation | ❌ Manual labeling required |
Hybrid AI Training: The 2026 Standard
The smartest AI teams aren't choosing between synthetic and real data — they're combining both. Hybrid AI Training blends human-curated real data (which anchors the model in ground truth), synthetic AI datasets (which expand coverage and edge cases), and Reinforcement Learning feedback (which sharpens decision-making). This three-way fusion is now the dominant paradigm at companies like Google DeepMind, Meta AI, and Anthropic.

Main Types & Real-World Use Cases
💡 Quick Answer: Synthetic data comes in fully synthetic, partially synthetic, and hybrid forms — spanning tabular, image, video, text, and multimodal formats. Real-world applications span autonomous vehicles, healthcare, fraud detection, and robotics.
Types of Synthetic Data:
Fully Synthetic — Entirely AI-generated with no connection to real records
Partially Synthetic — Real data with sensitive fields replaced by synthetic equivalents
Hybrid — Real data augmented with synthetic samples for coverage and balance
Data Modalities: Tabular, image, video, audio, text, and synthetic multimodal data (combining multiple formats simultaneously)
Real-World Use Cases:
🚗 Autonomous Vehicles — Waymo and Tesla use simulation-based synthetic data to train self-driving systems on millions of miles of rare accident scenarios, bad weather conditions, and edge-case traffic patterns that would be impossible — and dangerous — to collect in real life. NVIDIA Omniverse, paired with NVIDIA Cosmos world foundation models, creates what NVIDIA calls a "synthetic data multiplication engine" — generating massive volumes of controllable, photorealistic training data for physical AI.
🏥 Healthcare — Synthetic patient records allow hospitals and researchers to train diagnostic AI models on realistic clinical data without ever exposing real patient information. This is especially critical under HIPAA in the U.S. and medical data regulations globally.
💳 Fraud Detection — Fraud cases are, by definition, rare. A model that's never seen enough examples of a specific fraud type will miss it. Financial institutions generate synthetic fraudulent transactions at scale, dramatically improving detection accuracy without exposing real customer account data.
🤖 Robotics & Digital Twins — Companies like Agility Robotics and Figure AI use NVIDIA Cosmos to generate photorealistic synthetic training data for humanoid robots, compressing what would take years of real-world data collection into hours of simulation.
How is Synthetic Data in AI Transforming Generative AI?
💡 Quick Answer: Generative AI is running out of high-quality human-created content to train on. Synthetic data — particularly LLM-generated reasoning chains and simulation data — is enabling AI models to begin self-improving, marking a fundamental shift in how intelligence is developed.
The Internet Data Exhaustion Problem
Here is an uncomfortable truth sitting at the center of the AI industry right now: the internet is nearly scraped clean.
Researchers at Epoch AI have estimated that usable, high-quality human-written text on the internet will be effectively exhausted for training purposes somewhere between 2026 and 2032. Every major model — GPT, Gemini, Claude, Llama — was built primarily on this human-generated corpus. What happens when it runs out?
By April 2025, approximately 74.2% of newly created webpages already contained some AI-generated text. The web is being flooded with synthetic content faster than humans can produce original material.
This is precisely why synthetic data has moved from a supplementary tool to an existential necessity. The leading AI labs are now building systems that generate their own high-quality training data — particularly Synthetic Chain-of-Thought reasoning datasets — to continue improving without depending on the finite reservoir of human-written content.
Risks, Challenges, and "Model Collapse"
💡 Quick Answer: The greatest risk of over-reliance on synthetic data is Model Collapse — a degenerative process where AI models trained on AI-generated data progressively lose diversity, accuracy, and capability over successive generations.
In July 2024, a peer-reviewed study published in Nature by former Google DeepMind senior research scientist Ilia Shumailov and colleagues formally described model collapse: when AI models are repeatedly trained on outputs from earlier AI models, rare patterns disappear, outputs become increasingly bland and homogenous, and the model's understanding of reality narrows dangerously.
By 2025, an Apple research study found that large reasoning models face "complete accuracy collapse" on complex tasks when trained recursively on synthetic data.
The Synthetic Data Feedback Loop
The problem works like this:
Generation 1 AI → produces synthetic data → Generation 2 AI trains on it → produces more synthetic data → Generation 3 AI trains on that — and so on. With each cycle, statistical distortions compound. The model begins to forget the edges of reality — the rare, the unusual, the nuanced — and regresses toward a narrowing average. This is the synthetic data feedback loop, and it's one of the most serious challenges facing AI development in 2026.
Even moderate levels of synthetic contamination — as little as 1% of the training corpus — have been shown to begin triggering measurable degradation in model quality.
The Solution? Researchers broadly agree that the key is verification and mixing. Synthetic data must be filtered, validated against real-world anchors, and blended with human-curated data rather than used as a wholesale replacement.
Can Synthetic Data Replace Real Data?
💡 Quick Answer: No — not entirely. Synthetic data is a powerful augmentation tool, but real-world data remains the irreplaceable ground truth that keeps AI models accurate, generalizable, and trustworthy.
This is a question worth answering honestly, without hype. The consensus among researchers, practitioners, and even the AI community at large is clear: synthetic data augments real data; it does not replace it.
Real data carries something synthetic data cannot fully replicate — the messy, unexpected, deeply human complexity of the actual world. A synthetic dataset, no matter how well designed, is ultimately constrained by the assumptions baked into its generation process.
The practical model for 2026 and beyond is this: use real data to establish ground truth and anchor generalization, use privacy-preserving AI synthetic data to scale coverage and handle sensitive domains, and use Reinforcement Learning to refine behavior through feedback. Together, these three pillars form a training strategy that is more powerful — and more responsible — than any single source alone.
Best Synthetic Data Tools in 2026
💡 Quick Answer: The leading synthetic data platforms in 2026 include Mostly AI, Gretel AI, NVIDIA Omniverse, Datagen, Synthesis AI, and Tonic.ai — each serving different industries and data modalities.
Tool | Best For | Key Strength |
Mostly AI | Tabular data, finance, telecom | Privacy-safe structured data generation |
Gretel AI | Developers & ML teams | APIs for text, tabular & time-series data |
NVIDIA Omniverse + Cosmos | Robotics, AV, physical AI | Photorealistic simulation & digital twins |
Datagen | Computer vision, facial data | High-fidelity human-centric synthetic imagery |
Synthesis AI | Avatar & perception AI | Diverse human synthetic image generation |
Software testing & QA | De-identified production data mimicry |
The Future of Synthetic Data (2026–2030)
💡 Quick Answer: Between 2026 and 2030, synthetic data will move from a training tool to a core AI infrastructure layer — enabling autonomous scientific research, continuous self-improvement in AI systems, and fully simulated development environments.
The trajectory here is genuinely exciting. A few projections grounded in current research:
AI-Generated Scientific Research: Synthetic data is already being used to run in silico drug discovery trials, simulating molecular interactions that would take years of lab work. By 2028–2030, expect entire research pipelines — hypothesis, experiment, analysis — to run on synthetic environments.
Autonomous Self-Improvement: The combination of Synthetic Chain-of-Thought data and Reinforcement Learning from AI Feedback (RLAIF) is laying groundwork for models that iteratively improve their own reasoning without constant human intervention.
Multimodal Synthetic Training at Scale: By 2030, the leading models will be trained on synthetic datasets that seamlessly combine text, image, video, audio, and sensor data — generated entirely within controlled virtual environments. 971260623238
Regulation Will Catch Up: Expect global synthetic data governance frameworks to emerge between 2027 and 2029, standardizing how synthetic datasets are validated, certified, and used in high-stakes domains like healthcare and legal AI.

Frequently Asked Questions (FAQ)
Q1: What is synthetic data in AI? Synthetic data in AI is artificially generated data that statistically mirrors real-world datasets without containing actual personal information. It is created using GANs, diffusion models, LLMs, or rule-based systems.
Q2: Why is synthetic data important in 2026? Because real-world data is increasingly scarce, privacy regulations restrict data use, and the cost of manual data collection is prohibitive. Synthetic data solves all three problems simultaneously.
Q3: What is the difference between synthetic data and real data? Real data comes from actual events and people; synthetic data is algorithmically generated to mimic its statistical properties. Real data has higher authenticity; synthetic data offers greater privacy, scalability, and compliance.
Q4: What is model collapse in AI?
Model collapse is a degenerative process where AI models trained recursively on AI-generated data progressively lose diversity and accuracy, producing narrower and blander outputs over successive training generations.
Q5: Can synthetic data replace real data entirely?
No. The research consensus is that synthetic data is a powerful augmentation tool but cannot fully replace real data, which provides irreplaceable ground truth and real-world complexity.
Q6: What are GANs and how do they generate synthetic data? Generative Adversarial Networks (GANs) consist of two competing neural networks — a Generator and a Discriminator — that work in opposition until the Generator produces data realistic enough to fool the Discriminator.
Q7: What is Synthetic Chain-of-Thought data?
Synthetic Chain-of-Thought (CoT) data refers to AI-generated step-by-step reasoning sequences used to train smaller models to reason more effectively, a technique used prominently by OpenAI in its o1 and o3 model families.
Q8: How does synthetic data help in healthcare?
Synthetic patient records allow healthcare AI models to train on realistic clinical data without exposing real patient information, enabling HIPAA-compliant AI development in diagnosis, imaging, and treatment planning.
Q9: What is Hybrid AI Training?
Hybrid AI Training is the practice of combining real-world data, synthetic data, and reinforcement learning feedback in a single training pipeline — the dominant standard for leading AI labs in 2026.
Q10: What tools are used to generate synthetic data?
Leading platforms include Mostly AI, Gretel AI, NVIDIA Omniverse (with Cosmos), Datagen, Synthesis AI, and Tonic.ai — each specializing in different data types and industries.
References & Further Reading
This article is backed by authoritative sources and research. The following references were used to verify all claims, statistics, and technical information presented above.
Shumailov, I. et al. (2024) — "The Collapse of GPT" — Nature Journal. Foundational peer-reviewed research on model collapse. 🔗 https://cacm.acm.org/news/the-collapse-of-gpt/
Epoch AI Research (2024–2025) — Internet Data Exhaustion Projections (2026–2032). 🔗 https://epochai.org/
NVIDIA Newsroom (January 2025) — "NVIDIA Expands Omniverse With Generative Physical AI" — Official NVIDIA announcement on Cosmos WFMs and Omniverse Blueprints. 🔗 https://nvidianews.nvidia.com/news/nvidia-expands-omniverse-with-generative-physical-ai
NVIDIA Newsroom (2025) — "NVIDIA Announces Major Release of Cosmos World Foundation Models and Physical AI Data Tools." 🔗 https://nvidianews.nvidia.com/news/nvidia-announces-major-release-of-cosmos-world-foundation-models-and-physical-ai-data-tools
NVIDIA Omniverse Blog (October 2025) — "Into the Omniverse: Open World Foundation Models Generate Synthetic Worlds for Physical AI." 🔗 https://blogs.nvidia.com/blog/scaling-physical-ai-omniverse/
IBM Think (2026) — "What Is Model Collapse?" 🔗 https://www.ibm.com/think/topics/model-collapse
Cogent Infotech (2025) — "Synthetic Data Explosion: How 2026 Reduces Data Costs by 70%." 🔗 https://cogentinfo.com/resources/synthetic-data-explosion-how-2026-reduces-data-costs-by-70
AIM Multiple Research (2026) — "Top 25 Synthetic Data Use Cases." 🔗 https://aimultiple.com/synthetic-data-use-cases
TechTarget (2025) — "What is Synthetic Data? Examples, Use Cases and Benefits." 🔗 https://www.techtarget.com/searchcio/definition/synthetic-data
Abdel-Azim, A., Wang, R., & Lin, X. (2026) — "Harnessing Synthetic Data from Generative AI for Statistical Inference." arXiv preprint. 🔗 https://arxiv.org/pdf/2603.05396
⚠️ Disclaimer The information provided in this article is intended for general educational and informational purposes only. While the FourfoldAI Research Team has made every effort to ensure accuracy and cite authoritative sources, the field of AI evolves rapidly and some details may change after publication. This article does not constitute professional, legal, or financial advice. For our full disclaimer, please visit: https://www.fourfoldai.com/disclaimer
© 2026 FourfoldAI | Written by Shaikh Muizz, Senior AI Research Writer | fourfoldai.com



Comments